Izmēģiniet MI savā tīmekļa vietnē 60 sekundēs
Skatiet, kā mūsu MI acumirklī analizē jūsu tīmekļa vietni un izveido personalizētu tērzēšanas robotu - bez reģistrācijas. Vienkārši ievadiet savu URL un vērojiet, kā tas darbojas!
Gatavs 60 sekundēs
Nav nepieciešamas programmēšanas prasmes
100% droši
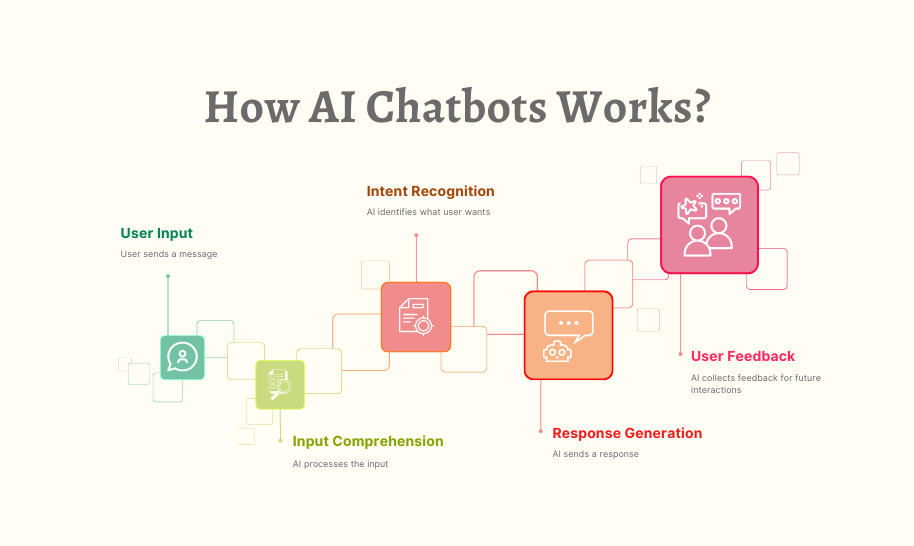
Kā faktiski darbojas mūsdienu tērzēšanas roboti
Katru dienu vietnēs, lietotnēs un ziņojumapmaiņas platformās notiek miljoniem sarunu ar AI tērzēšanas robotiem. Ierakstiet jautājumu, un pēc dažām sekundēm jūs saņemsit saskaņotu, noderīgu atbildi. Mijiedarbība šķiet arvien dabiskāka, dažreiz biedējošāka. Bet kas patiesībā notiek dažu sekunžu laikā starp jūsu jautājumu un tērzēšanas robota atbildi?
Mūsdienu tērzēšanas robotu šķietamā vienkāršība slēpj neticami izsmalcinātu tehnoloģisko orķestri, kas spēlē aizkulisēs. Tas, kas izskatās pēc vienkāršas teksta apmaiņas, ietver vairākas specializētas AI sistēmas, kas darbojas saskaņoti: apstrādā jūsu valodu, izgūst atbilstošu informāciju, ģenerē atbilstošas atbildes un nepārtraukti mācās no mijiedarbības.
Kā cilvēks, kurš ir pavadījis gadus, izstrādājot un ieviešot tērzēšanas robotu sistēmas dažādām nozarēm, esmu bijis pirmajā rindā to ievērojamajā attīstībā. Daudzi lietotāji ir pārsteigti, uzzinot, ka mūsdienu tērzēšanas roboti nav atsevišķas AI programmas, bet gan sarežģītas, specializētu komponentu ekosistēmas, kas darbojas kopā. Šo komponentu izpratne ne tikai atklāj to, kas dažkārt var šķist tehnoloģiskas burvības, bet arī palīdz mums labāk novērtēt gan to iespējas, gan ierobežojumus.
Šajā izpētē mēs atvilksim priekškaru mūsdienu tērzēšanas robotiem, lai izprastu galvenās tehnoloģijas, kas tos darbina, kā šīs sistēmas tiek apmācītas un kā tās pārvar cilvēku valodas pamatproblēmas. Neatkarīgi no tā, vai apsverat iespēju ieviest tērzēšanas robotu savam uzņēmumam vai vienkārši interesējaties par tehnoloģijām, ar kurām ikdienā mijiedarbojaties, šī aizkulišu apskate sniegs vērtīgu ieskatu vienā no AI redzamākajām lietojumprogrammām.
Mūsdienu tērzēšanas robotu šķietamā vienkāršība slēpj neticami izsmalcinātu tehnoloģisko orķestri, kas spēlē aizkulisēs. Tas, kas izskatās pēc vienkāršas teksta apmaiņas, ietver vairākas specializētas AI sistēmas, kas darbojas saskaņoti: apstrādā jūsu valodu, izgūst atbilstošu informāciju, ģenerē atbilstošas atbildes un nepārtraukti mācās no mijiedarbības.
Kā cilvēks, kurš ir pavadījis gadus, izstrādājot un ieviešot tērzēšanas robotu sistēmas dažādām nozarēm, esmu bijis pirmajā rindā to ievērojamajā attīstībā. Daudzi lietotāji ir pārsteigti, uzzinot, ka mūsdienu tērzēšanas roboti nav atsevišķas AI programmas, bet gan sarežģītas, specializētu komponentu ekosistēmas, kas darbojas kopā. Šo komponentu izpratne ne tikai atklāj to, kas dažkārt var šķist tehnoloģiskas burvības, bet arī palīdz mums labāk novērtēt gan to iespējas, gan ierobežojumus.
Šajā izpētē mēs atvilksim priekškaru mūsdienu tērzēšanas robotiem, lai izprastu galvenās tehnoloģijas, kas tos darbina, kā šīs sistēmas tiek apmācītas un kā tās pārvar cilvēku valodas pamatproblēmas. Neatkarīgi no tā, vai apsverat iespēju ieviest tērzēšanas robotu savam uzņēmumam vai vienkārši interesējaties par tehnoloģijām, ar kurām ikdienā mijiedarbojaties, šī aizkulišu apskate sniegs vērtīgu ieskatu vienā no AI redzamākajām lietojumprogrammām.
Fonds: lieli valodu modeļi
Mūsdienu visspējīgāko tērzēšanas robotu pamatā ir tehnoloģisks sasniegums, kas ir pārveidojis AI ainavu: lielie valodu modeļi (LLM). Šie milzīgie neironu tīkli, kas apmācīti, izmantojot nepieredzētu teksta datu apjomu, kalpo kā "smadzenes", kas mūsdienu tērzēšanas robotiem sniedz iespaidīgas spējas izprast un ģenerēt cilvēku valodu.
Šo modeļu mērogu ir grūti aptvert. Lielākajiem LLM ir simtiem miljardu parametru — regulējamās vērtības, ko modelis izmanto, lai veiktu prognozes. Apmācības laikā šie parametri tiek pakāpeniski pilnveidoti, jo modelis apstrādā lielas datu kopas, kas sastāv no grāmatām, rakstiem, vietnēm, kodu krātuvēm un cita teksta, kas bieži vien sasniedz triljoniem vārdu.
Izmantojot šo apmācības procesu, valodu modeļi veido statistisku izpratni par valodas darbību. Viņi apgūst vārdu krājumu, gramatiku, faktus par pasauli, spriešanas modeļus un pat zināmā mērā veselo saprātu. Svarīgi, ka viņi ne tikai iegaumē savus treniņu datus – viņi apgūst vispārināmus modeļus, kas ļauj apstrādāt jaunus ievades datus, ko viņi nekad nav redzējuši.
Nosūtot ziņojumu tērzēšanas robotam, kuru darbina LLM, jūsu teksts vispirms tiek pārveidots skaitliskās attēlos, ko sauc par marķieriem. Modelis apstrādā šos marķierus, izmantojot daudzos neironu savienojumu slāņus, galu galā izveidojot varbūtības sadalījumu, kādiem marķieriem vajadzētu nākt atbildē. Pēc tam sistēma pārvērš šos marķierus atpakaļ cilvēkiem lasāmā tekstā.
Mūsdienās vismodernākie valodu modeļi ietver:
GPT-4: OpenAI modelis nodrošina ChatGPT un daudzas citas komerciālas lietojumprogrammas, kas pazīstamas ar spēcīgajām spriešanas spējām un plašajām zināšanām.
Klods: Anthropic modeļu saime, kas veidota ar uzsvaru uz izpalīdzību, nekaitīgumu un godīgumu.
Llama 3: Meta atvērtie modeļi, kuriem ir demokratizēta piekļuve jaudīgai LLM tehnoloģijai.
Gemini: Google multimodālie modeļi, kas var apstrādāt gan tekstu, gan attēlus.
Mistral: efektīvu modeļu saime, kas nodrošina iespaidīgu veiktspēju, neskatoties uz mazāku parametru skaitu.
Neskatoties uz to ievērojamajām iespējām, pamata valodas modeļiem vien ir būtiski ierobežojumi kā sarunvalodas aģentiem. Viņiem nav piekļuves reāllaika informācijai, viņi nevar meklēt tīmeklī vai datu bāzēs, lai pārbaudītu faktus, un bieži “halucinē”, radot ticamu, bet nepareizu informāciju. Turklāt bez papildu pielāgošanas viņiem trūkst zināšanu par konkrētiem uzņēmumiem, produktiem vai lietotāju kontekstiem.
Tāpēc mūsdienu tērzēšanas robotu arhitektūras integrē LLM ar vairākiem citiem būtiskiem komponentiem, lai izveidotu patiesi noderīgas sarunu sistēmas.
Šo modeļu mērogu ir grūti aptvert. Lielākajiem LLM ir simtiem miljardu parametru — regulējamās vērtības, ko modelis izmanto, lai veiktu prognozes. Apmācības laikā šie parametri tiek pakāpeniski pilnveidoti, jo modelis apstrādā lielas datu kopas, kas sastāv no grāmatām, rakstiem, vietnēm, kodu krātuvēm un cita teksta, kas bieži vien sasniedz triljoniem vārdu.
Izmantojot šo apmācības procesu, valodu modeļi veido statistisku izpratni par valodas darbību. Viņi apgūst vārdu krājumu, gramatiku, faktus par pasauli, spriešanas modeļus un pat zināmā mērā veselo saprātu. Svarīgi, ka viņi ne tikai iegaumē savus treniņu datus – viņi apgūst vispārināmus modeļus, kas ļauj apstrādāt jaunus ievades datus, ko viņi nekad nav redzējuši.
Nosūtot ziņojumu tērzēšanas robotam, kuru darbina LLM, jūsu teksts vispirms tiek pārveidots skaitliskās attēlos, ko sauc par marķieriem. Modelis apstrādā šos marķierus, izmantojot daudzos neironu savienojumu slāņus, galu galā izveidojot varbūtības sadalījumu, kādiem marķieriem vajadzētu nākt atbildē. Pēc tam sistēma pārvērš šos marķierus atpakaļ cilvēkiem lasāmā tekstā.
Mūsdienās vismodernākie valodu modeļi ietver:
GPT-4: OpenAI modelis nodrošina ChatGPT un daudzas citas komerciālas lietojumprogrammas, kas pazīstamas ar spēcīgajām spriešanas spējām un plašajām zināšanām.
Klods: Anthropic modeļu saime, kas veidota ar uzsvaru uz izpalīdzību, nekaitīgumu un godīgumu.
Llama 3: Meta atvērtie modeļi, kuriem ir demokratizēta piekļuve jaudīgai LLM tehnoloģijai.
Gemini: Google multimodālie modeļi, kas var apstrādāt gan tekstu, gan attēlus.
Mistral: efektīvu modeļu saime, kas nodrošina iespaidīgu veiktspēju, neskatoties uz mazāku parametru skaitu.
Neskatoties uz to ievērojamajām iespējām, pamata valodas modeļiem vien ir būtiski ierobežojumi kā sarunvalodas aģentiem. Viņiem nav piekļuves reāllaika informācijai, viņi nevar meklēt tīmeklī vai datu bāzēs, lai pārbaudītu faktus, un bieži “halucinē”, radot ticamu, bet nepareizu informāciju. Turklāt bez papildu pielāgošanas viņiem trūkst zināšanu par konkrētiem uzņēmumiem, produktiem vai lietotāju kontekstiem.
Tāpēc mūsdienu tērzēšanas robotu arhitektūras integrē LLM ar vairākiem citiem būtiskiem komponentiem, lai izveidotu patiesi noderīgas sarunu sistēmas.
Izguves paplašinātā paaudze: tērzēšanas robotu iezemēšana faktos
Lai pārvarētu LLM zināšanu ierobežojumus, mūsdienu sarežģītākajās tērzēšanas robotu implementācijās ir iekļauta tehnika, ko sauc par izguves paplašināto paaudzi (RAG). Šī pieeja risina vienu no visbiežāk sastopamajām sūdzībām par AI palīgiem: viņu tieksmi pārliecinoši sniegt nepareizu informāciju.
RAG sistēmas darbojas, apvienojot valodu modeļu ģeneratīvās iespējas ar informācijas izguves sistēmu precizitāti. Lūk, kā modernā tērzēšanas robotā plūst tipisks RAG process:
Vaicājumu apstrāde: kad lietotājs uzdod jautājumu, sistēma to analizē, lai noteiktu galvenās informācijas vajadzības.
Informācijas izguve: tā vietā, lai paļautos tikai uz LLM apmācību datiem, sistēma meklē atbilstošās zināšanu bāzēs, kas var ietvert uzņēmuma dokumentāciju, produktu katalogus, FAQ vai pat vietnes reāllaika saturu.
Attiecīgā dokumenta atlase: izguves sistēma identificē visatbilstošākos dokumentus vai fragmentus, pamatojoties uz semantisko līdzību vaicājumam.
Konteksta palielināšana: šie izgūtie dokumenti tiek nodrošināti valodas modelim kā papildu konteksts, ģenerējot tā atbildi.
Atbilžu ģenerēšana: LLM sniedz atbildi, kas ietver gan vispārīgās valodas iespējas, gan specifisko izgūto informāciju.
Avota attiecinājums: daudzas RAG sistēmas arī izseko, kuri avoti ir devuši atbildi, ļaujot citēt vai pārbaudīt.
Šī pieeja apvieno labāko no abām pasaulēm: LLM spēju saprast jautājumus un ģenerēt dabisku valodu ar precizitāti un jaunāko informāciju no izguves sistēmām. Rezultāts ir tērzēšanas robots, kas var sniegt konkrētu, faktisku informāciju par produktiem, politikām vai pakalpojumiem, neizmantojot halucinācijas.
Apsveriet iespēju izveidot e-komercijas klientu apkalpošanas tērzēšanas robotu. Jautājot par atgriešanas politiku konkrētam produktam, tīrs LLM var radīt ticamu, bet potenciāli nepareizu atbildi, pamatojoties uz vispārīgiem modeļiem, ko tas novēroja apmācības laikā. Tā vietā RAG uzlabotais tērzēšanas robots izgūs uzņēmuma faktisko atgriešanas politikas dokumentu, atrod attiecīgo sadaļu par šo produktu kategoriju un ģenerē atbildi, kas precīzi atspoguļo pašreizējo politiku.
RAG sistēmu sarežģītība turpina attīstīties. Mūsdienu implementācijās tiek izmantotas blīvas vektoru iegulšanas, lai attēlotu gan vaicājumus, gan dokumentus augstas dimensijas semantiskajā telpā, ļaujot izgūt, pamatojoties uz nozīmi, nevis tikai atslēgvārdu atbilstību. Dažās sistēmās tiek izmantoti daudzpakāpju izguves cauruļvadi, vispirms izmetot platu tīklu un pēc tam precizējot rezultātus, veicot pārkārtošanu. Citi dinamiski nosaka, kad ir nepieciešama izguve, salīdzinot ar to, kad LLM var droši atbildēt, pamatojoties uz savām parametriskajām zināšanām.
Uzņēmumiem, kas ievieš tērzēšanas robotus, efektīvai RAG ieviešanai ir nepieciešama pārdomāta zināšanu bāzes sagatavošana – informācijas sakārtošana izgūstamos gabalos, regulāra satura atjaunināšana un datu strukturēšana tā, lai tie atvieglotu precīzu izguvi. Pareizi ieviešot, RAG ievērojami uzlabo tērzēšanas robotu precizitāti, īpaši domēnspecifiskām lietojumprogrammām, kur precizitāte ir ļoti svarīga.
RAG sistēmas darbojas, apvienojot valodu modeļu ģeneratīvās iespējas ar informācijas izguves sistēmu precizitāti. Lūk, kā modernā tērzēšanas robotā plūst tipisks RAG process:
Vaicājumu apstrāde: kad lietotājs uzdod jautājumu, sistēma to analizē, lai noteiktu galvenās informācijas vajadzības.
Informācijas izguve: tā vietā, lai paļautos tikai uz LLM apmācību datiem, sistēma meklē atbilstošās zināšanu bāzēs, kas var ietvert uzņēmuma dokumentāciju, produktu katalogus, FAQ vai pat vietnes reāllaika saturu.
Attiecīgā dokumenta atlase: izguves sistēma identificē visatbilstošākos dokumentus vai fragmentus, pamatojoties uz semantisko līdzību vaicājumam.
Konteksta palielināšana: šie izgūtie dokumenti tiek nodrošināti valodas modelim kā papildu konteksts, ģenerējot tā atbildi.
Atbilžu ģenerēšana: LLM sniedz atbildi, kas ietver gan vispārīgās valodas iespējas, gan specifisko izgūto informāciju.
Avota attiecinājums: daudzas RAG sistēmas arī izseko, kuri avoti ir devuši atbildi, ļaujot citēt vai pārbaudīt.
Šī pieeja apvieno labāko no abām pasaulēm: LLM spēju saprast jautājumus un ģenerēt dabisku valodu ar precizitāti un jaunāko informāciju no izguves sistēmām. Rezultāts ir tērzēšanas robots, kas var sniegt konkrētu, faktisku informāciju par produktiem, politikām vai pakalpojumiem, neizmantojot halucinācijas.
Apsveriet iespēju izveidot e-komercijas klientu apkalpošanas tērzēšanas robotu. Jautājot par atgriešanas politiku konkrētam produktam, tīrs LLM var radīt ticamu, bet potenciāli nepareizu atbildi, pamatojoties uz vispārīgiem modeļiem, ko tas novēroja apmācības laikā. Tā vietā RAG uzlabotais tērzēšanas robots izgūs uzņēmuma faktisko atgriešanas politikas dokumentu, atrod attiecīgo sadaļu par šo produktu kategoriju un ģenerē atbildi, kas precīzi atspoguļo pašreizējo politiku.
RAG sistēmu sarežģītība turpina attīstīties. Mūsdienu implementācijās tiek izmantotas blīvas vektoru iegulšanas, lai attēlotu gan vaicājumus, gan dokumentus augstas dimensijas semantiskajā telpā, ļaujot izgūt, pamatojoties uz nozīmi, nevis tikai atslēgvārdu atbilstību. Dažās sistēmās tiek izmantoti daudzpakāpju izguves cauruļvadi, vispirms izmetot platu tīklu un pēc tam precizējot rezultātus, veicot pārkārtošanu. Citi dinamiski nosaka, kad ir nepieciešama izguve, salīdzinot ar to, kad LLM var droši atbildēt, pamatojoties uz savām parametriskajām zināšanām.
Uzņēmumiem, kas ievieš tērzēšanas robotus, efektīvai RAG ieviešanai ir nepieciešama pārdomāta zināšanu bāzes sagatavošana – informācijas sakārtošana izgūstamos gabalos, regulāra satura atjaunināšana un datu strukturēšana tā, lai tie atvieglotu precīzu izguvi. Pareizi ieviešot, RAG ievērojami uzlabo tērzēšanas robotu precizitāti, īpaši domēnspecifiskām lietojumprogrammām, kur precizitāte ir ļoti svarīga.
Sarunu stāvokļa vadība: konteksta uzturēšana
Viens no vissarežģītākajiem cilvēku sarunas aspektiem ir tās kontekstuālais raksturs. Mēs atsaucamies uz iepriekšējiem apgalvojumiem, balstāmies uz kopīgu izpratni un sagaidām, ka citi sekos sarunas pavedienam, nepārtraukti neatkārtojot kontekstu. Agrīnie tērzēšanas roboti ļoti cīnījās ar šo komunikācijas aspektu, bieži vien "aizmirstot" to, kas tika apspriests tikai mirkli iepriekš.
Mūsdienu tērzēšanas roboti izmanto sarežģītas sarunvalodas stāvokļa pārvaldības sistēmas, lai uzturētu saskaņotu, kontekstuālu apmaiņu. Šīs sistēmas izseko ne tikai tiešo ziņojumu saturu, bet arī netiešo kontekstu, ko cilvēki, protams, uztur sarunu laikā.
Visvienkāršākā valsts pārvaldības forma ir sarunu vēstures izsekošana. Sistēma uztur jaunāko apmaiņu (gan lietotāja ievades, gan savu atbilžu) buferi, kas tiek nodrošināts valodas modelim ar katru jaunu vaicājumu. Tomēr, sarunām kļūstot garākai, visas vēstures iekļaušana kļūst nepraktiska pat vismodernāko LLM konteksta garuma ierobežojumu dēļ.
Lai novērstu šo ierobežojumu, sarežģīti tērzēšanas roboti izmanto vairākas metodes:
Kopsavilkums: periodiski sabiezināt iepriekšējās sarunas daļas kodolīgos kopsavilkos, kas tver galveno informāciju, vienlaikus samazinot marķiera izmantošanu.
Entītiju izsekošana: nepārprotami pārrauga sarunas laikā pieminētās svarīgas entītijas (cilvēki, produkti, problēmas) un uztur tās strukturētā stāvoklī.
Sarunas posma apzināšanās: izsekošana, kurā procesa plūsmā saruna pašlaik atrodas – vai vācot informāciju, piedāvājot risinājumus vai apstiprinot darbības.
Lietotāja konteksta noturība: atbilstošas lietotāja informācijas uzturēšana sesijās, piemēram, preferences, pirkumu vēsture vai konta informācija (ar atbilstošām konfidencialitātes vadīklām).
Nolūka atmiņa: lietotāja sākotnējā mērķa atcerēšanās, pat izmantojot sarunu apkārtceļus un precizējumus.
Apsveriet klientu apkalpošanas scenāriju: lietotājs sāk jautāt par abonēšanas plāna jaunināšanu, pēc tam uzdod vairākus detalizētus jautājumus par līdzekļiem, cenu salīdzinājumiem un norēķinu cikliem, pirms beidzot izlemj turpināt jaunināšanu. Efektīva sarunvalodas stāvokļa pārvaldības sistēma nodrošina, ka tad, kad lietotājs saka "Jā, darīsim to", tērzēšanas robots precīzi saprot, uz ko "tas" attiecas (jauninājums), un ir saglabājis visas atbilstošās detaļas no līkumotās sarunas.
Valsts pārvaldības tehniskā īstenošana dažādās platformās ir atšķirīga. Dažās sistēmās tiek izmantota hibrīda pieeja, apvienojot simbolisku stāvokļa izsekošanu (tieši modelējot entītijas un nolūkus) ar lielo konteksta logu netiešajām iespējām mūsdienu LLM. Citi izmanto specializētus atmiņas moduļus, kas selektīvi izgūst attiecīgās sarunu vēstures daļas, pamatojoties uz pašreizējo vaicājumu.
Sarežģītām lietojumprogrammām, piemēram, klientu apkalpošanai vai pārdošanai, stāvokļa pārvaldība bieži tiek integrēta ar biznesa procesu modelēšanu, ļaujot tērzēšanas robotiem vadīt sarunas noteiktās darbplūsmās, vienlaikus saglabājot elastīgumu dabiskai mijiedarbībai. Vismodernākās ieviešanas var pat izsekot emocionālajam stāvoklim līdzās faktiskajam kontekstam, pielāgojot komunikācijas stilu, pamatojoties uz atklāto lietotāja noskaņojumu.
Efektīva konteksta pārvaldība pārveido tērzēšanas robotu mijiedarbību no nesaistītas jautājumu un atbilžu apmaiņas par patiesām sarunām, kas balstās uz kopīgu izpratni, kas ir būtisks faktors lietotāju apmierinātības un uzdevumu izpildes rādītājos.
Mūsdienu tērzēšanas roboti izmanto sarežģītas sarunvalodas stāvokļa pārvaldības sistēmas, lai uzturētu saskaņotu, kontekstuālu apmaiņu. Šīs sistēmas izseko ne tikai tiešo ziņojumu saturu, bet arī netiešo kontekstu, ko cilvēki, protams, uztur sarunu laikā.
Visvienkāršākā valsts pārvaldības forma ir sarunu vēstures izsekošana. Sistēma uztur jaunāko apmaiņu (gan lietotāja ievades, gan savu atbilžu) buferi, kas tiek nodrošināts valodas modelim ar katru jaunu vaicājumu. Tomēr, sarunām kļūstot garākai, visas vēstures iekļaušana kļūst nepraktiska pat vismodernāko LLM konteksta garuma ierobežojumu dēļ.
Lai novērstu šo ierobežojumu, sarežģīti tērzēšanas roboti izmanto vairākas metodes:
Kopsavilkums: periodiski sabiezināt iepriekšējās sarunas daļas kodolīgos kopsavilkos, kas tver galveno informāciju, vienlaikus samazinot marķiera izmantošanu.
Entītiju izsekošana: nepārprotami pārrauga sarunas laikā pieminētās svarīgas entītijas (cilvēki, produkti, problēmas) un uztur tās strukturētā stāvoklī.
Sarunas posma apzināšanās: izsekošana, kurā procesa plūsmā saruna pašlaik atrodas – vai vācot informāciju, piedāvājot risinājumus vai apstiprinot darbības.
Lietotāja konteksta noturība: atbilstošas lietotāja informācijas uzturēšana sesijās, piemēram, preferences, pirkumu vēsture vai konta informācija (ar atbilstošām konfidencialitātes vadīklām).
Nolūka atmiņa: lietotāja sākotnējā mērķa atcerēšanās, pat izmantojot sarunu apkārtceļus un precizējumus.
Apsveriet klientu apkalpošanas scenāriju: lietotājs sāk jautāt par abonēšanas plāna jaunināšanu, pēc tam uzdod vairākus detalizētus jautājumus par līdzekļiem, cenu salīdzinājumiem un norēķinu cikliem, pirms beidzot izlemj turpināt jaunināšanu. Efektīva sarunvalodas stāvokļa pārvaldības sistēma nodrošina, ka tad, kad lietotājs saka "Jā, darīsim to", tērzēšanas robots precīzi saprot, uz ko "tas" attiecas (jauninājums), un ir saglabājis visas atbilstošās detaļas no līkumotās sarunas.
Valsts pārvaldības tehniskā īstenošana dažādās platformās ir atšķirīga. Dažās sistēmās tiek izmantota hibrīda pieeja, apvienojot simbolisku stāvokļa izsekošanu (tieši modelējot entītijas un nolūkus) ar lielo konteksta logu netiešajām iespējām mūsdienu LLM. Citi izmanto specializētus atmiņas moduļus, kas selektīvi izgūst attiecīgās sarunu vēstures daļas, pamatojoties uz pašreizējo vaicājumu.
Sarežģītām lietojumprogrammām, piemēram, klientu apkalpošanai vai pārdošanai, stāvokļa pārvaldība bieži tiek integrēta ar biznesa procesu modelēšanu, ļaujot tērzēšanas robotiem vadīt sarunas noteiktās darbplūsmās, vienlaikus saglabājot elastīgumu dabiskai mijiedarbībai. Vismodernākās ieviešanas var pat izsekot emocionālajam stāvoklim līdzās faktiskajam kontekstam, pielāgojot komunikācijas stilu, pamatojoties uz atklāto lietotāja noskaņojumu.
Efektīva konteksta pārvaldība pārveido tērzēšanas robotu mijiedarbību no nesaistītas jautājumu un atbilžu apmaiņas par patiesām sarunām, kas balstās uz kopīgu izpratni, kas ir būtisks faktors lietotāju apmierinātības un uzdevumu izpildes rādītājos.
Dabiskās valodas izpratne: lietotāja nodomu interpretācija
Lai tērzēšanas robots varētu formulēt atbilstošu atbildi, tam ir jāsaprot, ko lietotājs lūdz. Šis process, ko sauc par dabiskās valodas izpratni (NLU), ir atbildīgs par nozīmes izgūšanu no bieži vien neskaidrās, nepilnīgās vai neprecīzās valodas, ko cilvēki dabiski lieto.
Mūsdienu NLU sistēmas tērzēšanas robotos parasti veic vairākas galvenās funkcijas:
Nolūka atpazīšana: lietotāja pamata mērķa vai nolūka identificēšana. Vai lietotājs mēģina veikt pirkumu, ziņot par problēmu, pieprasīt informāciju vai kaut ko citu? Uzlabotas sistēmas var atpazīt vairākus vai ligzdotus nolūkus vienā ziņojumā.
Entītijas izvilkšana: noteiktu lietotāja ziņojumā esošās informācijas identificēšana un iedalīšana kategorijās. Piemēram, sadaļā “Man jāmaina lidojums no Čikāgas uz Bostonu ceturtdien” entītijas ietver atrašanās vietas (Čikāga, Bostona) un laiku (ceturtdiena).
Sentimenta analīze: emocionālā toņa un attieksmes noteikšana, kas palīdz tērzēšanas robotam atbilstoši pielāgot atbildes stilu. Vai lietotājs ir neapmierināts, satraukts, apmulsis vai neitrāls?
Valodas identifikācija: nosaka, kurā valodā lietotājs runā, lai sniegtu atbilstošas atbildes daudzvalodu vidē.
Lai gan agrākās tērzēšanas robotu platformās bija nepieciešama skaidra nodomu un entītiju programmēšana, mūsdienu sistēmas izmanto LLM raksturīgās valodas izpratnes iespējas. Tas viņiem ļauj apstrādāt daudz plašāku izteicienu klāstu, neprasot izsmeļošu iespējamo frāzējumu uzskaitījumu.
Kad lietotājs maksājuma lapā ieraksta “Norēķināšanās process turpina sasalst”, sarežģīta NLU sistēma to identificē kā tehniskā atbalsta nolūku, izņem “norēķinu procesu” un “maksājuma lapu” kā atbilstošās vienības, konstatē vilšanos noskaņojumā un novirza šo informāciju uz atbilstošo atbildes ģenerēšanas ceļu.
NLU precizitāte būtiski ietekmē lietotāju apmierinātību. Ja tērzēšanas robots pastāvīgi nepareizi interpretē pieprasījumus, lietotāji ātri zaudē uzticību un pacietību. Lai uzlabotu precizitāti, daudzās sistēmās tiek izmantots uzticamības novērtējums — ja pārliecība par sapratni nokrītas zem noteiktiem sliekšņiem, tērzēšanas robots var uzdot precizējošus jautājumus, nevis rīkoties ar iespējami nepareiziem pieņēmumiem.
Domēna specifiskām lietojumprogrammām NLU sistēmās bieži ir iekļauta specializēta terminoloģija un žargona atpazīšana. Piemēram, veselības aprūpes tērzēšanas robots būtu apmācīts atpazīt medicīniskos terminus un simptomus, savukārt finanšu pakalpojumu robots saprastu banku terminoloģiju un darījumu veidus.
NLU integrācija ar citiem komponentiem ir ļoti svarīga. Iegūtie nolūki un entītijas informē izguves procesus, palīdz uzturēt sarunu stāvokli un vadīt atbildes ģenerēšanu, kas kalpo kā kritiskā saikne starp lietotāju teikto un sistēmas darbību.
Mūsdienu NLU sistēmas tērzēšanas robotos parasti veic vairākas galvenās funkcijas:
Nolūka atpazīšana: lietotāja pamata mērķa vai nolūka identificēšana. Vai lietotājs mēģina veikt pirkumu, ziņot par problēmu, pieprasīt informāciju vai kaut ko citu? Uzlabotas sistēmas var atpazīt vairākus vai ligzdotus nolūkus vienā ziņojumā.
Entītijas izvilkšana: noteiktu lietotāja ziņojumā esošās informācijas identificēšana un iedalīšana kategorijās. Piemēram, sadaļā “Man jāmaina lidojums no Čikāgas uz Bostonu ceturtdien” entītijas ietver atrašanās vietas (Čikāga, Bostona) un laiku (ceturtdiena).
Sentimenta analīze: emocionālā toņa un attieksmes noteikšana, kas palīdz tērzēšanas robotam atbilstoši pielāgot atbildes stilu. Vai lietotājs ir neapmierināts, satraukts, apmulsis vai neitrāls?
Valodas identifikācija: nosaka, kurā valodā lietotājs runā, lai sniegtu atbilstošas atbildes daudzvalodu vidē.
Lai gan agrākās tērzēšanas robotu platformās bija nepieciešama skaidra nodomu un entītiju programmēšana, mūsdienu sistēmas izmanto LLM raksturīgās valodas izpratnes iespējas. Tas viņiem ļauj apstrādāt daudz plašāku izteicienu klāstu, neprasot izsmeļošu iespējamo frāzējumu uzskaitījumu.
Kad lietotājs maksājuma lapā ieraksta “Norēķināšanās process turpina sasalst”, sarežģīta NLU sistēma to identificē kā tehniskā atbalsta nolūku, izņem “norēķinu procesu” un “maksājuma lapu” kā atbilstošās vienības, konstatē vilšanos noskaņojumā un novirza šo informāciju uz atbilstošo atbildes ģenerēšanas ceļu.
NLU precizitāte būtiski ietekmē lietotāju apmierinātību. Ja tērzēšanas robots pastāvīgi nepareizi interpretē pieprasījumus, lietotāji ātri zaudē uzticību un pacietību. Lai uzlabotu precizitāti, daudzās sistēmās tiek izmantots uzticamības novērtējums — ja pārliecība par sapratni nokrītas zem noteiktiem sliekšņiem, tērzēšanas robots var uzdot precizējošus jautājumus, nevis rīkoties ar iespējami nepareiziem pieņēmumiem.
Domēna specifiskām lietojumprogrammām NLU sistēmās bieži ir iekļauta specializēta terminoloģija un žargona atpazīšana. Piemēram, veselības aprūpes tērzēšanas robots būtu apmācīts atpazīt medicīniskos terminus un simptomus, savukārt finanšu pakalpojumu robots saprastu banku terminoloģiju un darījumu veidus.
NLU integrācija ar citiem komponentiem ir ļoti svarīga. Iegūtie nolūki un entītijas informē izguves procesus, palīdz uzturēt sarunu stāvokli un vadīt atbildes ģenerēšanu, kas kalpo kā kritiskā saikne starp lietotāju teikto un sistēmas darbību.
Izmēģiniet MI savā tīmekļa vietnē 60 sekundēs
Skatiet, kā mūsu MI acumirklī analizē jūsu tīmekļa vietni un izveido personalizētu tērzēšanas robotu - bez reģistrācijas. Vienkārši ievadiet savu URL un vērojiet, kā tas darbojas!
Gatavs 60 sekundēs
Nav nepieciešamas programmēšanas prasmes
100% droši
Atbildes ģenerēšana un optimizācija
Kad tērzēšanas robots ir sapratis lietotāja vaicājumu un ir apkopojis atbilstošu kontekstu un informāciju, tam ir jāizstrādā atbilstoša atbilde. Šajā komponentā, ko bieži sauc par dabiskās valodas ģenerēšanu (NLG), sistēmas “personība” un efektivitāte lietotājiem ir visredzamākā.
Mūsdienu sistēmās atbilžu ģenerēšana parasti ietver vairākus posmus:
Atbildes plānošana: informācijas, jautājumu vai ieteicamo darbību noteikšana, pamatojoties uz pašreizējo sarunas stāvokli un pieejamajām zināšanām.
Satura atlase: konkrētu faktu, skaidrojumu vai iespēju izvēle no potenciāli lieliem atbilstošas informācijas kopumiem.
Strukturēšana: atlasītā satura organizēšana loģiskā, viegli izpildāmā secībā, kas efektīvi atbilst lietotāja vajadzībām.
Realizācija: plānotā satura pārveidošana dabiskā, plūstošā valodā, kas atbilst tērzēšanas robota vēlamajam tonim un stilam.
Lai gan dabiskās valodas ģenerēšana var ģenerēt iespaidīgi saskaņotu tekstu, nekontrolēta ģenerēšana bieži rada tādas problēmas kā pārmērīga daudzvārdība, neatbilstošas informācijas iekļaušana vai atbildes, kas neatbilst biznesa mērķiem. Lai risinātu šīs problēmas, sarežģītas tērzēšanas robotu sistēmas ievieš dažādas optimizācijas metodes:
Atbilžu veidnes: Bieži sastopamiem scenārijiem ar paredzamām informācijas vajadzībām daudzas sistēmas izmanto parametrizētas veidnes, kas nodrošina konsekventas un efektīvas atbildes, vienlaikus ļaujot personalizēt.
Garuma kontrole: Mehānismi atbildes garuma pielāgošanai, pamatojoties uz vaicājuma sarežģītību, platformu, kurā notiek mijiedarbība, un lietotāja preferencēm.
Toņa un stila vadlīnijas: Norādījumi, kas pielāgo atbilžu formalitāti, draudzīgumu vai tehnisko līmeni, pamatojoties uz sarunas kontekstu un lietotāja īpašībām.
Vairāku kārtu plānošana: Sarežģītām tēmām sistēmas var plānot atbildes vairākās kārtās, apzināti sadalot informāciju viegli uztveramos fragmentos, nevis pārslogojot lietotājus ar teksta sienām.
Biznesa loģikas integrācija: Noteikumi, kas nodrošina, ka atbildes atbilst biznesa politikām, normatīvajām prasībām un pakalpojumu iespējām.
Visefektīvākie tērzēšanas roboti izmanto arī adaptīvas atbilžu stratēģijas. Tie uzrauga lietotāju iesaisti un apmierinātības signālus, lai laika gaitā pilnveidotu savu komunikācijas pieeju. Ja lietotāji bieži lūdz skaidrojumus pēc noteikta veida atbildes, sistēma var automātiski pielāgoties, lai sniegtu detalizētākus skaidrojumus līdzīgos nākotnes scenārijos.
Izšķirošs atbilžu ģenerēšanas aspekts ir nenoteiktības pārvaldība. Ja informācija nav pieejama vai ir neskaidra, labi izstrādātas sistēmas atzīst ierobežojumus, nevis ģenerē pārliecinoši skanošas, bet potenciāli nepareizas atbildes. Šī pārredzamība veicina uzticēšanos un efektīvi pārvalda lietotāju cerības.
Misijai kritiski svarīgās lietojumprogrammās, piemēram, veselības aprūpē vai finanšu pakalpojumos, daudzās ieviešanas reizēs ir iekļauti cilvēka pārskatīšanas mehānismi noteikta veida atbildēm, pirms tās sasniedz lietotājus. Šīs aizsargbarjeras nodrošina papildu kvalitātes kontroles slāni mijiedarbībai ar augstām likmēm.
Mūsdienu sistēmās atbilžu ģenerēšana parasti ietver vairākus posmus:
Atbildes plānošana: informācijas, jautājumu vai ieteicamo darbību noteikšana, pamatojoties uz pašreizējo sarunas stāvokli un pieejamajām zināšanām.
Satura atlase: konkrētu faktu, skaidrojumu vai iespēju izvēle no potenciāli lieliem atbilstošas informācijas kopumiem.
Strukturēšana: atlasītā satura organizēšana loģiskā, viegli izpildāmā secībā, kas efektīvi atbilst lietotāja vajadzībām.
Realizācija: plānotā satura pārveidošana dabiskā, plūstošā valodā, kas atbilst tērzēšanas robota vēlamajam tonim un stilam.
Lai gan dabiskās valodas ģenerēšana var ģenerēt iespaidīgi saskaņotu tekstu, nekontrolēta ģenerēšana bieži rada tādas problēmas kā pārmērīga daudzvārdība, neatbilstošas informācijas iekļaušana vai atbildes, kas neatbilst biznesa mērķiem. Lai risinātu šīs problēmas, sarežģītas tērzēšanas robotu sistēmas ievieš dažādas optimizācijas metodes:
Atbilžu veidnes: Bieži sastopamiem scenārijiem ar paredzamām informācijas vajadzībām daudzas sistēmas izmanto parametrizētas veidnes, kas nodrošina konsekventas un efektīvas atbildes, vienlaikus ļaujot personalizēt.
Garuma kontrole: Mehānismi atbildes garuma pielāgošanai, pamatojoties uz vaicājuma sarežģītību, platformu, kurā notiek mijiedarbība, un lietotāja preferencēm.
Toņa un stila vadlīnijas: Norādījumi, kas pielāgo atbilžu formalitāti, draudzīgumu vai tehnisko līmeni, pamatojoties uz sarunas kontekstu un lietotāja īpašībām.
Vairāku kārtu plānošana: Sarežģītām tēmām sistēmas var plānot atbildes vairākās kārtās, apzināti sadalot informāciju viegli uztveramos fragmentos, nevis pārslogojot lietotājus ar teksta sienām.
Biznesa loģikas integrācija: Noteikumi, kas nodrošina, ka atbildes atbilst biznesa politikām, normatīvajām prasībām un pakalpojumu iespējām.
Visefektīvākie tērzēšanas roboti izmanto arī adaptīvas atbilžu stratēģijas. Tie uzrauga lietotāju iesaisti un apmierinātības signālus, lai laika gaitā pilnveidotu savu komunikācijas pieeju. Ja lietotāji bieži lūdz skaidrojumus pēc noteikta veida atbildes, sistēma var automātiski pielāgoties, lai sniegtu detalizētākus skaidrojumus līdzīgos nākotnes scenārijos.
Izšķirošs atbilžu ģenerēšanas aspekts ir nenoteiktības pārvaldība. Ja informācija nav pieejama vai ir neskaidra, labi izstrādātas sistēmas atzīst ierobežojumus, nevis ģenerē pārliecinoši skanošas, bet potenciāli nepareizas atbildes. Šī pārredzamība veicina uzticēšanos un efektīvi pārvalda lietotāju cerības.
Misijai kritiski svarīgās lietojumprogrammās, piemēram, veselības aprūpē vai finanšu pakalpojumos, daudzās ieviešanas reizēs ir iekļauti cilvēka pārskatīšanas mehānismi noteikta veida atbildēm, pirms tās sasniedz lietotājus. Šīs aizsargbarjeras nodrošina papildu kvalitātes kontroles slāni mijiedarbībai ar augstām likmēm.
Specializēti moduļi darbībām un integrācijai
Mūsdienu tērzēšanas roboti dara daudz vairāk, nekā tikai atbild uz jautājumiem – tie veic darbības lietotāju vārdā, integrējoties ar dažādām biznesa sistēmām, lai sniegtu visaptverošu pakalpojumu. Šī iespēja pārveido tos no informatīviem rīkiem par funkcionāliem palīgiem, kas faktiski var atrisināt problēmas no gala līdz galam.
Šīs darbības iespējas tiek īstenotas, izmantojot specializētus moduļus, kas savieno sarunu saskarni ar ārējām sistēmām:
API integrācijas ietvars: starpprogrammatūras slānis, kas pārvērš sarunu pieprasījumus pareizi formatētos API izsaukumos uz dažādiem aizmugures pakalpojumiem – pasūtīšanas sistēmām, CRM platformām, maksājumu apstrādātājiem, rezervēšanas sistēmām utt.
Autentifikācija un autorizācija: drošības komponenti, kas pārbauda lietotāja identitāti un atļauju līmeņus pirms sensitīvu darbību veikšanas vai piekļuves aizsargātai informācijai.
Veidlapu aizpildīšanas palīdzība: moduļi, kas palīdz lietotājiem aizpildīt sarežģītas veidlapas, izmantojot sarunvalodas mijiedarbību, apkopojot nepieciešamo informāciju pa daļām, nevis sniedzot milzīgas veidlapas.
Darījumu apstrāde: komponenti, kas apstrādā daudzpakāpju procesus, piemēram, pirkumus, rezervācijas vai konta izmaiņas, saglabā stāvokli visa procesa laikā un graciozi apstrādā izņēmumus.
Paziņojumu sistēmas: iespējas nosūtīt atjauninājumus, apstiprinājumus vai brīdinājumus, izmantojot dažādus kanālus (e-pastu, SMS, paziņojumus lietotnē), kad darbības norit vai tiek pabeigtas.
Šo integrāciju sarežģītība dažādās implementācijās ir ļoti atšķirīga. Vienkāršos tērzēšanas robotos var būt ietverta pamata "nodošanas" funkcionalitāte, kas pārsūta lietotājus uz cilvēku aģentiem vai specializētām sistēmām, kad nepieciešama darbība. Uzlabotas ieviešanas iespējas nodrošina netraucētu pilnīgu pieredzi, kur tērzēšanas robots apstrādā visu sarunas procesu.
Apsveriet iespēju izmantot aviokompānijas tērzēšanas robotu, kas palīdz pasažierim mainīt lidojumu. Tam nepieciešams:
Autentificējiet lietotāju un izgūstiet viņa rezervāciju
Meklējiet pieejamos alternatīvos lidojumus
Aprēķiniet cenas atšķirības vai mainiet maksu
Ja nepieciešams, apstrādājiet maksājumu
Izsniedziet jaunas iekāpšanas kartes
Atjauniniet rezervāciju vairākās sistēmās
Nosūtiet apstiprinājuma informāciju, izmantojot vēlamos kanālus
Lai to paveiktu, ir nepieciešama integrācija ar rezervēšanas sistēmām, maksājumu apstrādātājiem, autentifikācijas pakalpojumiem un paziņojumu platformām — to visu organizē tērzēšanas robots, vienlaikus saglabājot dabisku sarunu plūsmu.
Uzņēmumiem, kas veido uz darbību orientētus tērzēšanas robotus, šis integrācijas slānis bieži vien ir visnozīmīgākais izstrādes darbs. Lai gan sarunvalodas komponenti gūst labumu no vispārējas nozīmes AI sasniegumiem, šīs integrācijas ir jāveido pēc pasūtījuma katras organizācijas specifiskajai sistēmu ainavai.
Drošības apsvērumi ir īpaši svarīgi tērzēšanas robotiem, kas spēj darboties. Labākā prakse ietver pareizas autentifikācijas ieviešanu pirms sensitīvām darbībām, detalizētu visu veikto darbību audita žurnālu uzturēšanu, skaidru apstiprinājuma darbību nodrošināšanu secīgām darbībām un graciozu kļūmju apstrādes plānošanu, ja integrācijas saskaras ar problēmām.
Paplašinoties šīm integrācijas iespējām, robeža starp sarunvalodas saskarnēm un tradicionālajām lietojumprogrammām turpina izplūst. Mūsdienās vissarežģītākās ieviešanas iespējas ļauj lietotājiem veikt sarežģītus uzdevumus, izmantojot dabisku sarunu, kas iepriekš būtu prasījusi navigāciju vairākos ekrānos tradicionālajās lietojumprogrammās.
Šīs darbības iespējas tiek īstenotas, izmantojot specializētus moduļus, kas savieno sarunu saskarni ar ārējām sistēmām:
API integrācijas ietvars: starpprogrammatūras slānis, kas pārvērš sarunu pieprasījumus pareizi formatētos API izsaukumos uz dažādiem aizmugures pakalpojumiem – pasūtīšanas sistēmām, CRM platformām, maksājumu apstrādātājiem, rezervēšanas sistēmām utt.
Autentifikācija un autorizācija: drošības komponenti, kas pārbauda lietotāja identitāti un atļauju līmeņus pirms sensitīvu darbību veikšanas vai piekļuves aizsargātai informācijai.
Veidlapu aizpildīšanas palīdzība: moduļi, kas palīdz lietotājiem aizpildīt sarežģītas veidlapas, izmantojot sarunvalodas mijiedarbību, apkopojot nepieciešamo informāciju pa daļām, nevis sniedzot milzīgas veidlapas.
Darījumu apstrāde: komponenti, kas apstrādā daudzpakāpju procesus, piemēram, pirkumus, rezervācijas vai konta izmaiņas, saglabā stāvokli visa procesa laikā un graciozi apstrādā izņēmumus.
Paziņojumu sistēmas: iespējas nosūtīt atjauninājumus, apstiprinājumus vai brīdinājumus, izmantojot dažādus kanālus (e-pastu, SMS, paziņojumus lietotnē), kad darbības norit vai tiek pabeigtas.
Šo integrāciju sarežģītība dažādās implementācijās ir ļoti atšķirīga. Vienkāršos tērzēšanas robotos var būt ietverta pamata "nodošanas" funkcionalitāte, kas pārsūta lietotājus uz cilvēku aģentiem vai specializētām sistēmām, kad nepieciešama darbība. Uzlabotas ieviešanas iespējas nodrošina netraucētu pilnīgu pieredzi, kur tērzēšanas robots apstrādā visu sarunas procesu.
Apsveriet iespēju izmantot aviokompānijas tērzēšanas robotu, kas palīdz pasažierim mainīt lidojumu. Tam nepieciešams:
Autentificējiet lietotāju un izgūstiet viņa rezervāciju
Meklējiet pieejamos alternatīvos lidojumus
Aprēķiniet cenas atšķirības vai mainiet maksu
Ja nepieciešams, apstrādājiet maksājumu
Izsniedziet jaunas iekāpšanas kartes
Atjauniniet rezervāciju vairākās sistēmās
Nosūtiet apstiprinājuma informāciju, izmantojot vēlamos kanālus
Lai to paveiktu, ir nepieciešama integrācija ar rezervēšanas sistēmām, maksājumu apstrādātājiem, autentifikācijas pakalpojumiem un paziņojumu platformām — to visu organizē tērzēšanas robots, vienlaikus saglabājot dabisku sarunu plūsmu.
Uzņēmumiem, kas veido uz darbību orientētus tērzēšanas robotus, šis integrācijas slānis bieži vien ir visnozīmīgākais izstrādes darbs. Lai gan sarunvalodas komponenti gūst labumu no vispārējas nozīmes AI sasniegumiem, šīs integrācijas ir jāveido pēc pasūtījuma katras organizācijas specifiskajai sistēmu ainavai.
Drošības apsvērumi ir īpaši svarīgi tērzēšanas robotiem, kas spēj darboties. Labākā prakse ietver pareizas autentifikācijas ieviešanu pirms sensitīvām darbībām, detalizētu visu veikto darbību audita žurnālu uzturēšanu, skaidru apstiprinājuma darbību nodrošināšanu secīgām darbībām un graciozu kļūmju apstrādes plānošanu, ja integrācijas saskaras ar problēmām.
Paplašinoties šīm integrācijas iespējām, robeža starp sarunvalodas saskarnēm un tradicionālajām lietojumprogrammām turpina izplūst. Mūsdienās vissarežģītākās ieviešanas iespējas ļauj lietotājiem veikt sarežģītus uzdevumus, izmantojot dabisku sarunu, kas iepriekš būtu prasījusi navigāciju vairākos ekrānos tradicionālajās lietojumprogrammās.
Apmācība un nepārtraukta pilnveidošanās
Atšķirībā no tradicionālās programmatūras, kas paliek statiska līdz nepārprotamai atjaunināšanai, mūsdienu tērzēšanas roboti izmanto dažādus nepārtrauktas mācīšanās un uzlabošanas mehānismus. Šī evolūcijas spēja ļauj viņiem laika gaitā uzlaboties, pielāgojoties lietotāju vajadzībām un novēršot trūkumus viņu spējās.
Vairākas pieejas apmācību un uzlabošanas darbam saskaņoti:
Pamata modeļa precizēšana: pamata valodu modeļus, kas darbina tērzēšanas robotus, var turpināt specializēt, izmantojot papildu apmācību par domēna specifiskiem datiem. Šis process, ko sauc par precizēšanu, palīdz modelim pieņemt atbilstošu terminoloģiju, argumentācijas modeļus un domēna zināšanas konkrētām lietojumprogrammām.
Mācību pastiprināšana no cilvēku atsauksmēm (RLHF): šī metode izmanto cilvēku vērtētājus, lai novērtētu modeļa atbildes, izveidojot preferenču datus, kas apmāca atalgojuma modeļus. Šie atalgojuma modeļi virza sistēmu uz noderīgāku, precīzāku un drošāku rezultātu ģenerēšanu. RLHF ir bijusi izšķiroša nozīme valodu modeļu pārveidē no iespaidīgiem, bet neuzticamiem ģeneratoriem uz praktiskiem palīgiem.
Sarunu ieguve: Analytics sistēmas, kas apstrādā anonimizētus sarunu žurnālus, lai identificētu modeļus, bieži uzdotos jautājumus, biežus kļūmju punktus un veiksmīgas atrisināšanas ceļus. Šie ieskati veicina gan automatizētus uzlabojumus, gan cilvēku vadītus uzlabojumus.
Aktīvā mācīšanās: sistēmas, kas identificē nenoteiktības jomas un atzīmē šos gadījumus cilvēku pārskatīšanai, koncentrējot cilvēku pūles uz visvērtīgākajām uzlabošanas iespējām.
A/B testēšana: eksperimentālās sistēmas, kas salīdzina dažādas atbildes stratēģijas ar reāliem lietotājiem, lai noteiktu, kuras pieejas ir visefektīvākās dažādos scenārijos.
Uzņēmuma tērzēšanas robotiem apmācības process parasti sākas ar vēsturiskiem datiem – iepriekšējiem klientu apkalpošanas stenogrammām, dokumentāciju un informāciju par produktu. Pēc tam šī sākotnējā apmācība tiek papildināta ar rūpīgi izstrādātām sarunām, kas parāda ideālu parasto scenāriju risināšanu.
Pēc izvietošanas efektīvās sistēmas ietver atgriezeniskās saites mehānismus, kas lietotājiem ļauj norādīt, vai atbildes bija noderīgas. Šīs atsauksmes apvienojumā ar netiešiem signāliem, piemēram, sarunas pārtraukšanu vai atkārtotiem jautājumiem, veido bagātīgu datu kopu nepārtrauktiem uzlabojumiem.
Cilvēka loma mūsdienu tērzēšanas robotu apmācībā joprojām ir būtiska. Sarunu dizaineri veido personības un saziņas modeļus. Priekšmeta eksperti izskata un labo piedāvātās atbildes, lai nodrošinātu tehnisko precizitāti. Datu zinātnieki analizē veiktspējas rādītājus, lai noteiktu uzlabošanas iespējas. Veiksmīgākās ieviešanas tērzēšanas robotu izstrāde tiek uzskatīta par cilvēka un AI sadarbības partnerību, nevis pilnībā automatizētu procesu.
Uzņēmumiem, kas ievieš tērzēšanas robotus, ir ļoti svarīgi izveidot skaidru uzlabojumu sistēmu. Tas ietver:
Regulāri veiktspējas pārskatīšanas cikli
Uzraudzībai un uzlabošanai veltīts personāls
Skaidri panākumu rādītāji
Lietotāju atsauksmju iekļaušanas procesi
Apmācības datu kvalitātes pārvaldības pārvaldība
Lai gan īpašās pieejas dažādās platformās un lietojumprogrammās atšķiras, pamatprincips paliek nemainīgs: mūsdienu tērzēšanas roboti ir dinamiskas sistēmas, kas uzlabojas, izmantojot lietošanu, atgriezenisko saiti un apzinātu pilnveidošanu, nevis statiskas programmas, kas ir bloķētas to sākotnējās iespējās.
Vairākas pieejas apmācību un uzlabošanas darbam saskaņoti:
Pamata modeļa precizēšana: pamata valodu modeļus, kas darbina tērzēšanas robotus, var turpināt specializēt, izmantojot papildu apmācību par domēna specifiskiem datiem. Šis process, ko sauc par precizēšanu, palīdz modelim pieņemt atbilstošu terminoloģiju, argumentācijas modeļus un domēna zināšanas konkrētām lietojumprogrammām.
Mācību pastiprināšana no cilvēku atsauksmēm (RLHF): šī metode izmanto cilvēku vērtētājus, lai novērtētu modeļa atbildes, izveidojot preferenču datus, kas apmāca atalgojuma modeļus. Šie atalgojuma modeļi virza sistēmu uz noderīgāku, precīzāku un drošāku rezultātu ģenerēšanu. RLHF ir bijusi izšķiroša nozīme valodu modeļu pārveidē no iespaidīgiem, bet neuzticamiem ģeneratoriem uz praktiskiem palīgiem.
Sarunu ieguve: Analytics sistēmas, kas apstrādā anonimizētus sarunu žurnālus, lai identificētu modeļus, bieži uzdotos jautājumus, biežus kļūmju punktus un veiksmīgas atrisināšanas ceļus. Šie ieskati veicina gan automatizētus uzlabojumus, gan cilvēku vadītus uzlabojumus.
Aktīvā mācīšanās: sistēmas, kas identificē nenoteiktības jomas un atzīmē šos gadījumus cilvēku pārskatīšanai, koncentrējot cilvēku pūles uz visvērtīgākajām uzlabošanas iespējām.
A/B testēšana: eksperimentālās sistēmas, kas salīdzina dažādas atbildes stratēģijas ar reāliem lietotājiem, lai noteiktu, kuras pieejas ir visefektīvākās dažādos scenārijos.
Uzņēmuma tērzēšanas robotiem apmācības process parasti sākas ar vēsturiskiem datiem – iepriekšējiem klientu apkalpošanas stenogrammām, dokumentāciju un informāciju par produktu. Pēc tam šī sākotnējā apmācība tiek papildināta ar rūpīgi izstrādātām sarunām, kas parāda ideālu parasto scenāriju risināšanu.
Pēc izvietošanas efektīvās sistēmas ietver atgriezeniskās saites mehānismus, kas lietotājiem ļauj norādīt, vai atbildes bija noderīgas. Šīs atsauksmes apvienojumā ar netiešiem signāliem, piemēram, sarunas pārtraukšanu vai atkārtotiem jautājumiem, veido bagātīgu datu kopu nepārtrauktiem uzlabojumiem.
Cilvēka loma mūsdienu tērzēšanas robotu apmācībā joprojām ir būtiska. Sarunu dizaineri veido personības un saziņas modeļus. Priekšmeta eksperti izskata un labo piedāvātās atbildes, lai nodrošinātu tehnisko precizitāti. Datu zinātnieki analizē veiktspējas rādītājus, lai noteiktu uzlabošanas iespējas. Veiksmīgākās ieviešanas tērzēšanas robotu izstrāde tiek uzskatīta par cilvēka un AI sadarbības partnerību, nevis pilnībā automatizētu procesu.
Uzņēmumiem, kas ievieš tērzēšanas robotus, ir ļoti svarīgi izveidot skaidru uzlabojumu sistēmu. Tas ietver:
Regulāri veiktspējas pārskatīšanas cikli
Uzraudzībai un uzlabošanai veltīts personāls
Skaidri panākumu rādītāji
Lietotāju atsauksmju iekļaušanas procesi
Apmācības datu kvalitātes pārvaldības pārvaldība
Lai gan īpašās pieejas dažādās platformās un lietojumprogrammās atšķiras, pamatprincips paliek nemainīgs: mūsdienu tērzēšanas roboti ir dinamiskas sistēmas, kas uzlabojas, izmantojot lietošanu, atgriezenisko saiti un apzinātu pilnveidošanu, nevis statiskas programmas, kas ir bloķētas to sākotnējās iespējās.
Aizsardzības pasākumi un ētiski apsvērumi
Tā kā tērzēšanas roboti ir kļuvuši sarežģītāki un plaši izplatīti, drošības mehānismu un ētikas vadlīniju nozīme kļūst arvien skaidrāka. Mūsdienu atbildīgākās ieviešanas veidi ietver vairākus aizsardzības līmeņus, lai novērstu ļaunprātīgu izmantošanu, nodrošinātu atbilstošu uzvedību un aizsargātu gan lietotājus, gan uzņēmumus.
Šie aizsargpasākumi parasti ietver:
Satura filtrēšana: sistēmas, kas atklāj un novērš kaitīgu, aizskarošu vai nepiemērotu saturu gan lietotāja ievadītajā, gan modeļa izvadē. Mūsdienu ieviešanā tiek izmantoti specializēti modeļi, kas īpaši apmācīti identificēt problemātisku saturu dažādās kategorijās.
Darbības jomas izpilde: mehānismi, kas uztur sarunas atbilstošos domēnos, neļaujot manipulēt ar tērzēšanas robotiem, lai sniegtu padomus vai informāciju, kas neatbilst tiem paredzētajam mērķim un kompetencei.
Datu konfidencialitātes kontrole: sensitīvas lietotāju informācijas aizsardzība, tostarp datu samazināšanas principi, anonimizācijas paņēmieni un nepārprotamas piekrišanas mehānismi datu glabāšanai vai lietošanai.
Neobjektivitātes mazināšana: procesi, kas identificē un samazina netaisnīgu novirzi apmācības datos un modeļu iznākumos, nodrošinot vienlīdzīgu attieksmi pret dažādām lietotāju grupām.
Ārējo atsauču pārbaude: faktu apgalvojumiem, jo īpaši sensitīvos domēnos, sistēmas, kas pārbauda informāciju, salīdzinot ar uzticamiem ārējiem avotiem, pirms to sniedz lietotājiem.
Cilvēka uzraudzība: kritiskām lietojumprogrammām pārskatiet mehānismus, kas nodrošina cilvēka uzraudzību un vajadzības gadījumā iejaukšanos, jo īpaši saistībā ar izrietošiem lēmumiem vai sensitīvām tēmām.
Šo aizsardzības pasākumu īstenošana ietver gan tehniskos, gan politikas komponentus. Tehniskajā līmenī dažādi filtrēšanas modeļi, noteikšanas algoritmi un uzraudzības sistēmas darbojas kopā, lai identificētu problemātiskas mijiedarbības. Politikas līmenī skaidras vadlīnijas nosaka piemērotus lietošanas gadījumus, nepieciešamās atrunas un eskalācijas ceļus.
Veselības aprūpes tērzēšanas roboti sniedz skaidru piemēru šiem principiem darbībā. Labi izstrādātas sistēmas šajā domēnā parasti ietver nepārprotamas atrunas par to ierobežojumiem, izvairās no diagnostikas valodas, ja vien tas nav medicīniski apstiprināts, uztur stingru veselības informācijas konfidencialitātes kontroli un iekļauj skaidrus ceļus, kā sazināties ar medicīnas speciālistiem, lai noskaidrotu attiecīgās bažas.
Uzņēmumiem, kas ievieš tērzēšanas robotus, ir parādījušās vairākas labākās prakses:
Sāciet ar skaidrām ētikas vadlīnijām un lietošanas gadījumu robežām
Ieviesiet vairākus drošības mehānismu līmeņus, nevis paļaujieties uz vienu pieeju
Plaši pārbaudiet ar dažādām lietotāju grupām un scenārijiem
Izveidojiet uzraudzības un incidentu reaģēšanas protokolus
Sniedziet lietotājiem pārskatāmu informāciju par sistēmas iespējām un ierobežojumiem
Sarunu AI kļūstot spēcīgākam, šo aizsardzības pasākumu nozīme tikai palielinās. Veiksmīgākās ieviešanas procesā inovācija ir līdzsvarota ar atbildību, nodrošinot, ka tērzēšanas roboti joprojām ir noderīgi rīki, kas uzlabo cilvēku spējas, nevis rada jaunus riskus vai kaitējumu.
Šie aizsargpasākumi parasti ietver:
Satura filtrēšana: sistēmas, kas atklāj un novērš kaitīgu, aizskarošu vai nepiemērotu saturu gan lietotāja ievadītajā, gan modeļa izvadē. Mūsdienu ieviešanā tiek izmantoti specializēti modeļi, kas īpaši apmācīti identificēt problemātisku saturu dažādās kategorijās.
Darbības jomas izpilde: mehānismi, kas uztur sarunas atbilstošos domēnos, neļaujot manipulēt ar tērzēšanas robotiem, lai sniegtu padomus vai informāciju, kas neatbilst tiem paredzētajam mērķim un kompetencei.
Datu konfidencialitātes kontrole: sensitīvas lietotāju informācijas aizsardzība, tostarp datu samazināšanas principi, anonimizācijas paņēmieni un nepārprotamas piekrišanas mehānismi datu glabāšanai vai lietošanai.
Neobjektivitātes mazināšana: procesi, kas identificē un samazina netaisnīgu novirzi apmācības datos un modeļu iznākumos, nodrošinot vienlīdzīgu attieksmi pret dažādām lietotāju grupām.
Ārējo atsauču pārbaude: faktu apgalvojumiem, jo īpaši sensitīvos domēnos, sistēmas, kas pārbauda informāciju, salīdzinot ar uzticamiem ārējiem avotiem, pirms to sniedz lietotājiem.
Cilvēka uzraudzība: kritiskām lietojumprogrammām pārskatiet mehānismus, kas nodrošina cilvēka uzraudzību un vajadzības gadījumā iejaukšanos, jo īpaši saistībā ar izrietošiem lēmumiem vai sensitīvām tēmām.
Šo aizsardzības pasākumu īstenošana ietver gan tehniskos, gan politikas komponentus. Tehniskajā līmenī dažādi filtrēšanas modeļi, noteikšanas algoritmi un uzraudzības sistēmas darbojas kopā, lai identificētu problemātiskas mijiedarbības. Politikas līmenī skaidras vadlīnijas nosaka piemērotus lietošanas gadījumus, nepieciešamās atrunas un eskalācijas ceļus.
Veselības aprūpes tērzēšanas roboti sniedz skaidru piemēru šiem principiem darbībā. Labi izstrādātas sistēmas šajā domēnā parasti ietver nepārprotamas atrunas par to ierobežojumiem, izvairās no diagnostikas valodas, ja vien tas nav medicīniski apstiprināts, uztur stingru veselības informācijas konfidencialitātes kontroli un iekļauj skaidrus ceļus, kā sazināties ar medicīnas speciālistiem, lai noskaidrotu attiecīgās bažas.
Uzņēmumiem, kas ievieš tērzēšanas robotus, ir parādījušās vairākas labākās prakses:
Sāciet ar skaidrām ētikas vadlīnijām un lietošanas gadījumu robežām
Ieviesiet vairākus drošības mehānismu līmeņus, nevis paļaujieties uz vienu pieeju
Plaši pārbaudiet ar dažādām lietotāju grupām un scenārijiem
Izveidojiet uzraudzības un incidentu reaģēšanas protokolus
Sniedziet lietotājiem pārskatāmu informāciju par sistēmas iespējām un ierobežojumiem
Sarunu AI kļūstot spēcīgākam, šo aizsardzības pasākumu nozīme tikai palielinās. Veiksmīgākās ieviešanas procesā inovācija ir līdzsvarota ar atbildību, nodrošinot, ka tērzēšanas roboti joprojām ir noderīgi rīki, kas uzlabo cilvēku spējas, nevis rada jaunus riskus vai kaitējumu.
Chatbot tehnoloģijas nākotne
Lai gan mūsdienu tērzēšanas roboti ir ļoti tālu no saviem primitīvajiem senčiem, tehnoloģija turpina strauji attīstīties. Vairākas jaunas tendences norāda, kur tuvākajā nākotnē virzīsies sarunvalodas AI:
Multimodālas iespējas: nākamās paaudzes tērzēšanas roboti pāries ārpus teksta, nemanāmi iekļaujot attēlus, balsi, video un interaktīvus elementus. Lietotāji varēs parādīt problēmas, izmantojot savu kameru, dzirdēt paskaidrojumus ar vizuāliem palīglīdzekļiem un mijiedarboties, izmantojot jebkuru līdzekli, kas ir ērtākais viņu pašreizējam kontekstam.
Aģentiskā uzvedība: uzlabotie tērzēšanas roboti pāriet no reaktīvas atbildes uz jautājumiem uz proaktīvu problēmu risināšanu. Šīs "aģentiskās" sistēmas var uzņemties iniciatīvu, sadalīt sarežģītus uzdevumus soļos, izmantot rīkus informācijas vākšanai un pastāvēt, līdz tiek sasniegti mērķi – vairāk kā virtuālie palīgi, nevis vienkārši tērzēšanas roboti.
Atmiņa un personalizēšana: nākotnes sistēmas saglabās sarežģītāku ilgtermiņa atmiņu par lietotāja vēlmēm, pagātnes mijiedarbību un attiecību vēsturi. Šī pastāvīgā izpratne ļaus iegūt arvien personalizētāku pieredzi, kas pielāgojas individuālajiem komunikācijas stiliem, zināšanu līmeņiem un vajadzībām.
Specializēti domēnu eksperti: lai gan vispārējas nozīmes tērzēšanas roboti turpinās uzlaboties, mēs redzam arī ļoti specializētu sistēmu parādīšanos ar dziļām zināšanām konkrētās jomās — juristu palīgus ar vispusīgām zināšanām par judikatūru, medicīnas sistēmām, kas apmācītas klīniskajā literatūrā, vai finanšu konsultantus, kas pārzina nodokļu kodeksus un noteikumus.
Sadarbības inteliģence: robeža starp cilvēku un mākslīgā intelekta pienākumiem turpinās izplūdināt, izmantojot sarežģītākus sadarbības modeļus, kuros tērzēšanas roboti un cilvēku eksperti strādā nevainojami, katrs apstrādājot klientu mijiedarbības aspektus, kur tie ir izcili.
Emocionālā inteliģence: Sasniegumi ietekmes atpazīšanā un atbilstošas emocionālās reakcijas ģenerēšanā radīs dabiski empātiskāku mijiedarbību. Nākotnes sistēmas labāk atpazīs smalkas emocionālas norādes un reaģēs ar atbilstošu jutīgumu uz lietotāju vajadzībām.
Federatīvā apstrāde un apstrāde ierīcē: Privātuma problēmas veicina tādu arhitektūru attīstību, kurās vairāk apstrādes notiek lokāli lietotāju ierīcēs, un uz centrālajiem serveriem tiek pārsūtīts mazāk datu. Šī pieeja sola labāku privātuma aizsardzību, vienlaikus saglabājot sarežģītas iespējas.
Šie sasniegumi nodrošinās jaunas lietojumprogrammas visās nozarēs. Veselības aprūpē tērzēšanas roboti var kalpot kā nepārtraukti veselības pavadoņi, uzraugot apstākļus un koordinējot aprūpi starp pakalpojumu sniedzējiem. Izglītībā viņi varētu darboties kā personalizēti pasniedzēji, kas pielāgojas individuālajiem mācīšanās stiliem un progresam. Profesionālajos pakalpojumos viņi varētu kļūt par specializētiem pētniecības palīgiem, kas ievērojami paplašina cilvēku zināšanas.
Tomēr šīs iespējas radīs arī jaunus izaicinājumus. Jaudīgākām sistēmām būs nepieciešami sarežģītāki drošības mehānismi. Arvien vairāk cilvēkiem līdzīga mijiedarbība radīs jaunus jautājumus par atbilstošu AI identitātes izpaušanu. Tā kā šīs sistēmas arvien vairāk integrējas ikdienas dzīvē, vienlīdzīgas piekļuves nodrošināšana un kaitīgas atkarības novēršana kļūs par svarīgiem sociālajiem apsvērumiem.
Šķiet skaidrs, ka robeža starp tērzēšanas robotiem un citām programmatūras saskarnēm turpinās izplūst. Dabiskā valoda ir vienkārši intuitīvākā saskarne daudzām cilvēku vajadzībām, un, tā kā sarunvalodas AI kļūst arvien spējīgākas, tā arvien vairāk kļūs par noklusējuma veidu, kā mēs mijiedarbojamies ar digitālajām sistēmām. Nākotne nav saistīta tikai ar labākiem tērzēšanas robotiem — runa ir par to, lai saruna kļūtu par galveno cilvēka un datora saskarni daudzām lietojumprogrammām.
Secinājums: notiekošā saruna
Mūsdienu tērzēšanas roboti ir viens no redzamākajiem un ietekmīgākajiem mākslīgā intelekta lietojumiem ikdienas dzīvē. Aiz viņu šķietami vienkāršajām tērzēšanas saskarnēm slēpjas sarežģīts tehnoloģiju orķestris, kas darbojas saskaņoti: pamata modeļi, kas nodrošina valodas izpratni, izguves sistēmas, kas nodrošina atbildes precīzā informācijā, valsts vadība, kas uztur saskaņotas sarunas, integrācijas slāņi, kas savieno ar biznesa sistēmām, un drošības mehānismi, kas nodrošina atbilstošu uzvedību.
Šī sarežģītā arhitektūra nodrošina pieredzi, kas vēl pirms desmit gadiem šķita kā zinātniskā fantastika – dabiskas sarunas ar digitālajām sistēmām, kas spēj atbildēt uz jautājumiem, atrisināt problēmas un veikt darbības mūsu vārdā. Un tomēr mēs joprojām atrodamies šīs tehnoloģijas attīstības sākumā. Sarunu AI iespējas un lietojumprogrammas turpmākajos gados turpinās strauji paplašināties.
Uzņēmumiem un organizācijām, kas vēlas ieviest tērzēšanas robotu tehnoloģiju, šo pamatā esošo komponentu izpratne ir ļoti svarīga, lai izvirzītu reālas cerības, izdarītu apzinātu dizaina izvēli un radītu patiesi vērtīgu lietotāja pieredzi. Veiksmīgākās implementācijas tērzēšanas robotus neuzskata par maģiskām melnām kastēm, bet gan par sarežģītiem rīkiem, kuru iespējas un ierobežojumi ir pārdomāti jāpārvalda.
Lietotājiem, kuri mijiedarbojas ar šīm sistēmām, ieskats aiz priekškara var palīdzēt atklāt to, kas dažkārt šķiet kā tehnoloģiska maģija. Izpratne par mūsdienu tērzēšanas robotu darbības pamatprincipiem nodrošina efektīvāku mijiedarbību — zinot, kad tie var palīdzēt, kad viņiem var rasties grūtības un kā ar tiem sazināties visveiksmīgāk.
Iespējams, visievērojamākais tērzēšanas robotu tehnoloģijā ir tas, cik ātri pielāgojas mūsu cerības. Funkcijas, kas mūs būtu pārsteigušas pirms dažiem gadiem, ātri kļuva par bāzes līniju, ko mēs uzskatām par pašsaprotamu. Šī straujā normalizācija runā par to, cik dabiski saruna darbojas kā saskarne — ja tā tiek veikta labi, tā vienkārši pazūd, liekot mums koncentrēties uz problēmu risināšanu un lietu paveikšanu, nevis domāt par pašu tehnoloģiju.
Šīm sistēmām turpinot attīstīties, saruna starp cilvēkiem un mašīnām kļūs arvien nemanāmāka un produktīvāka — tā neaizstās cilvēku saikni, bet gan uzlabos mūsu spējas un ļaus mums koncentrēties uz mūsu darba un dzīves unikāli cilvēciskajiem aspektiem.
Multimodālas iespējas: nākamās paaudzes tērzēšanas roboti pāries ārpus teksta, nemanāmi iekļaujot attēlus, balsi, video un interaktīvus elementus. Lietotāji varēs parādīt problēmas, izmantojot savu kameru, dzirdēt paskaidrojumus ar vizuāliem palīglīdzekļiem un mijiedarboties, izmantojot jebkuru līdzekli, kas ir ērtākais viņu pašreizējam kontekstam.
Aģentiskā uzvedība: uzlabotie tērzēšanas roboti pāriet no reaktīvas atbildes uz jautājumiem uz proaktīvu problēmu risināšanu. Šīs "aģentiskās" sistēmas var uzņemties iniciatīvu, sadalīt sarežģītus uzdevumus soļos, izmantot rīkus informācijas vākšanai un pastāvēt, līdz tiek sasniegti mērķi – vairāk kā virtuālie palīgi, nevis vienkārši tērzēšanas roboti.
Atmiņa un personalizēšana: nākotnes sistēmas saglabās sarežģītāku ilgtermiņa atmiņu par lietotāja vēlmēm, pagātnes mijiedarbību un attiecību vēsturi. Šī pastāvīgā izpratne ļaus iegūt arvien personalizētāku pieredzi, kas pielāgojas individuālajiem komunikācijas stiliem, zināšanu līmeņiem un vajadzībām.
Specializēti domēnu eksperti: lai gan vispārējas nozīmes tērzēšanas roboti turpinās uzlaboties, mēs redzam arī ļoti specializētu sistēmu parādīšanos ar dziļām zināšanām konkrētās jomās — juristu palīgus ar vispusīgām zināšanām par judikatūru, medicīnas sistēmām, kas apmācītas klīniskajā literatūrā, vai finanšu konsultantus, kas pārzina nodokļu kodeksus un noteikumus.
Sadarbības inteliģence: robeža starp cilvēku un mākslīgā intelekta pienākumiem turpinās izplūdināt, izmantojot sarežģītākus sadarbības modeļus, kuros tērzēšanas roboti un cilvēku eksperti strādā nevainojami, katrs apstrādājot klientu mijiedarbības aspektus, kur tie ir izcili.
Emocionālā inteliģence: Sasniegumi ietekmes atpazīšanā un atbilstošas emocionālās reakcijas ģenerēšanā radīs dabiski empātiskāku mijiedarbību. Nākotnes sistēmas labāk atpazīs smalkas emocionālas norādes un reaģēs ar atbilstošu jutīgumu uz lietotāju vajadzībām.
Federatīvā apstrāde un apstrāde ierīcē: Privātuma problēmas veicina tādu arhitektūru attīstību, kurās vairāk apstrādes notiek lokāli lietotāju ierīcēs, un uz centrālajiem serveriem tiek pārsūtīts mazāk datu. Šī pieeja sola labāku privātuma aizsardzību, vienlaikus saglabājot sarežģītas iespējas.
Šie sasniegumi nodrošinās jaunas lietojumprogrammas visās nozarēs. Veselības aprūpē tērzēšanas roboti var kalpot kā nepārtraukti veselības pavadoņi, uzraugot apstākļus un koordinējot aprūpi starp pakalpojumu sniedzējiem. Izglītībā viņi varētu darboties kā personalizēti pasniedzēji, kas pielāgojas individuālajiem mācīšanās stiliem un progresam. Profesionālajos pakalpojumos viņi varētu kļūt par specializētiem pētniecības palīgiem, kas ievērojami paplašina cilvēku zināšanas.
Tomēr šīs iespējas radīs arī jaunus izaicinājumus. Jaudīgākām sistēmām būs nepieciešami sarežģītāki drošības mehānismi. Arvien vairāk cilvēkiem līdzīga mijiedarbība radīs jaunus jautājumus par atbilstošu AI identitātes izpaušanu. Tā kā šīs sistēmas arvien vairāk integrējas ikdienas dzīvē, vienlīdzīgas piekļuves nodrošināšana un kaitīgas atkarības novēršana kļūs par svarīgiem sociālajiem apsvērumiem.
Šķiet skaidrs, ka robeža starp tērzēšanas robotiem un citām programmatūras saskarnēm turpinās izplūst. Dabiskā valoda ir vienkārši intuitīvākā saskarne daudzām cilvēku vajadzībām, un, tā kā sarunvalodas AI kļūst arvien spējīgākas, tā arvien vairāk kļūs par noklusējuma veidu, kā mēs mijiedarbojamies ar digitālajām sistēmām. Nākotne nav saistīta tikai ar labākiem tērzēšanas robotiem — runa ir par to, lai saruna kļūtu par galveno cilvēka un datora saskarni daudzām lietojumprogrammām.
Secinājums: notiekošā saruna
Mūsdienu tērzēšanas roboti ir viens no redzamākajiem un ietekmīgākajiem mākslīgā intelekta lietojumiem ikdienas dzīvē. Aiz viņu šķietami vienkāršajām tērzēšanas saskarnēm slēpjas sarežģīts tehnoloģiju orķestris, kas darbojas saskaņoti: pamata modeļi, kas nodrošina valodas izpratni, izguves sistēmas, kas nodrošina atbildes precīzā informācijā, valsts vadība, kas uztur saskaņotas sarunas, integrācijas slāņi, kas savieno ar biznesa sistēmām, un drošības mehānismi, kas nodrošina atbilstošu uzvedību.
Šī sarežģītā arhitektūra nodrošina pieredzi, kas vēl pirms desmit gadiem šķita kā zinātniskā fantastika – dabiskas sarunas ar digitālajām sistēmām, kas spēj atbildēt uz jautājumiem, atrisināt problēmas un veikt darbības mūsu vārdā. Un tomēr mēs joprojām atrodamies šīs tehnoloģijas attīstības sākumā. Sarunu AI iespējas un lietojumprogrammas turpmākajos gados turpinās strauji paplašināties.
Uzņēmumiem un organizācijām, kas vēlas ieviest tērzēšanas robotu tehnoloģiju, šo pamatā esošo komponentu izpratne ir ļoti svarīga, lai izvirzītu reālas cerības, izdarītu apzinātu dizaina izvēli un radītu patiesi vērtīgu lietotāja pieredzi. Veiksmīgākās implementācijas tērzēšanas robotus neuzskata par maģiskām melnām kastēm, bet gan par sarežģītiem rīkiem, kuru iespējas un ierobežojumi ir pārdomāti jāpārvalda.
Lietotājiem, kuri mijiedarbojas ar šīm sistēmām, ieskats aiz priekškara var palīdzēt atklāt to, kas dažkārt šķiet kā tehnoloģiska maģija. Izpratne par mūsdienu tērzēšanas robotu darbības pamatprincipiem nodrošina efektīvāku mijiedarbību — zinot, kad tie var palīdzēt, kad viņiem var rasties grūtības un kā ar tiem sazināties visveiksmīgāk.
Iespējams, visievērojamākais tērzēšanas robotu tehnoloģijā ir tas, cik ātri pielāgojas mūsu cerības. Funkcijas, kas mūs būtu pārsteigušas pirms dažiem gadiem, ātri kļuva par bāzes līniju, ko mēs uzskatām par pašsaprotamu. Šī straujā normalizācija runā par to, cik dabiski saruna darbojas kā saskarne — ja tā tiek veikta labi, tā vienkārši pazūd, liekot mums koncentrēties uz problēmu risināšanu un lietu paveikšanu, nevis domāt par pašu tehnoloģiju.
Šīm sistēmām turpinot attīstīties, saruna starp cilvēkiem un mašīnām kļūs arvien nemanāmāka un produktīvāka — tā neaizstās cilvēku saikni, bet gan uzlabos mūsu spējas un ļaus mums koncentrēties uz mūsu darba un dzīves unikāli cilvēciskajiem aspektiem.





