Pārbaudiet SAVU Biznesu Minūtes
Izveidojiet savu kontu un palaidiet savu AI chatbot dažu minūšu laikā. Pilnībā pielāgojams, nav nepieciešama kodēšana - sāciet iesaistīt savus klientus tūlīt!
Gatavs dažu minūšu laikā
Nav nepieciešama kodēšana
100% droši
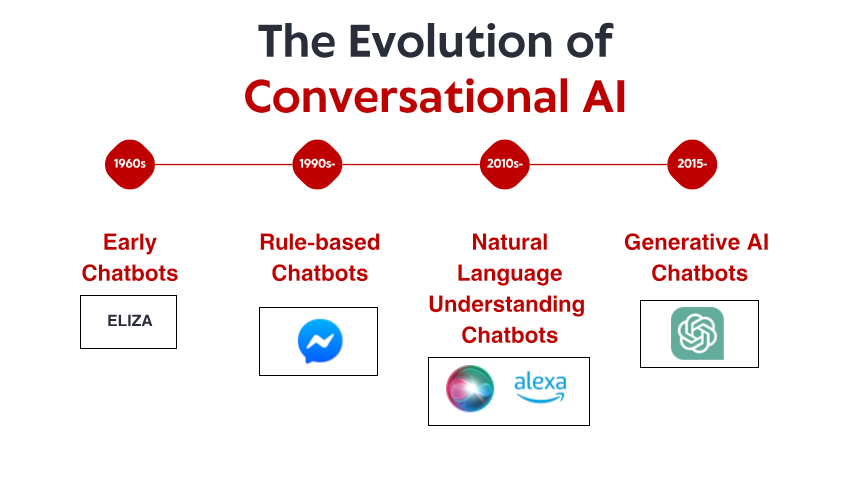
Pieticīgie sākumi: agrīnās uz noteikumiem balstītās sistēmas
Sarunvalodas mākslīgā intelekta stāsts sākas 20. gs. sešdesmitajos gados, ilgi pirms viedtālruņi un balss asistenti kļuva par mājsaimniecības pamatlietām. Nelielā MIT laboratorijā datorzinātnieks Džozefs Veizenbaums izveidoja robotu, ko daudzi uzskata par pirmo tērzēšanas robotu: ELIZA. Izstrādāts, lai simulētu Rodžersa psihoterapeitu, ELIZA strādāja, izmantojot vienkāršus modeļu saskaņošanas un aizstāšanas noteikumus. Kad lietotājs ierakstīja "Es jūtos skumji", ELIZA varēja atbildēt ar "Kāpēc tu jūties skumji?", radot izpratnes ilūziju, pārformulējot apgalvojumus kā jautājumus.
ELIZA ievērojamu padarīja nevis tās tehniskā sarežģītība — pēc mūsdienu standartiem programma bija neticami vienkārša. Drīzāk tā bija dziļā ietekme, ko tā atstāja uz lietotājiem. Neskatoties uz to, ka zināja, ka viņi runā ar datorprogrammu bez faktiskas izpratnes, daudzi cilvēki veidoja emocionālu saikni ar ELIZA, daloties dziļi personīgās domās un sajūtās. Šī parādība, ko pats Veizenbaums uzskatīja par satraucošu, atklāja kaut ko fundamentālu par cilvēka psiholoģiju un mūsu vēlmi antropomorfizēt pat vienkāršākās sarunu saskarnes. Visu 20. gs. 70. un 80. gados uz noteikumiem balstīti tērzēšanas roboti sekoja ELIZA veidnei ar pakāpeniskiem uzlabojumiem. Tādas programmas kā PARRY (simulējot paranoīdu šizofrēniķi) un RACTER (kas "autorēja" grāmatu ar nosaukumu "Policista bārda ir puskonstruēta") stingri palika uz noteikumiem balstītas paradigmas ietvaros, izmantojot iepriekš definētus modeļus, atslēgvārdu saskaņošanu un veidņu atbildes.
Šīm agrīnajām sistēmām bija nopietni ierobežojumi. Tās faktiski nevarēja saprast valodu, mācīties no mijiedarbības vai pielāgoties negaidītiem ievades datiem. To zināšanas aprobežojās ar noteikumiem, ko bija skaidri definējuši viņu programmētāji. Kad lietotāji neizbēgami novirzījās ārpus šīm robežām, intelekta ilūzija ātri vien sabruka, atklājot pamatā esošo mehānisko dabu. Neskatoties uz šiem ierobežojumiem, šīs novatoriskās sistēmas izveidoja pamatu, uz kura balstīsies viss nākotnes sarunu mākslīgais intelekts.
ELIZA ievērojamu padarīja nevis tās tehniskā sarežģītība — pēc mūsdienu standartiem programma bija neticami vienkārša. Drīzāk tā bija dziļā ietekme, ko tā atstāja uz lietotājiem. Neskatoties uz to, ka zināja, ka viņi runā ar datorprogrammu bez faktiskas izpratnes, daudzi cilvēki veidoja emocionālu saikni ar ELIZA, daloties dziļi personīgās domās un sajūtās. Šī parādība, ko pats Veizenbaums uzskatīja par satraucošu, atklāja kaut ko fundamentālu par cilvēka psiholoģiju un mūsu vēlmi antropomorfizēt pat vienkāršākās sarunu saskarnes. Visu 20. gs. 70. un 80. gados uz noteikumiem balstīti tērzēšanas roboti sekoja ELIZA veidnei ar pakāpeniskiem uzlabojumiem. Tādas programmas kā PARRY (simulējot paranoīdu šizofrēniķi) un RACTER (kas "autorēja" grāmatu ar nosaukumu "Policista bārda ir puskonstruēta") stingri palika uz noteikumiem balstītas paradigmas ietvaros, izmantojot iepriekš definētus modeļus, atslēgvārdu saskaņošanu un veidņu atbildes.
Šīm agrīnajām sistēmām bija nopietni ierobežojumi. Tās faktiski nevarēja saprast valodu, mācīties no mijiedarbības vai pielāgoties negaidītiem ievades datiem. To zināšanas aprobežojās ar noteikumiem, ko bija skaidri definējuši viņu programmētāji. Kad lietotāji neizbēgami novirzījās ārpus šīm robežām, intelekta ilūzija ātri vien sabruka, atklājot pamatā esošo mehānisko dabu. Neskatoties uz šiem ierobežojumiem, šīs novatoriskās sistēmas izveidoja pamatu, uz kura balstīsies viss nākotnes sarunu mākslīgais intelekts.
Zināšanu revolūcija: ekspertu sistēmas un strukturēta informācija
Astoņdesmitajos un deviņdesmito gadu sākumā parādījās ekspertu sistēmas – mākslīgā intelekta programmas, kas paredzētas sarežģītu problēmu risināšanai, atdarinot cilvēku ekspertu lēmumu pieņemšanas spējas konkrētās jomās. Lai gan šīs sistēmas nebija galvenokārt paredzētas sarunām, tās bija svarīgs evolūcijas solis sarunvalodas mākslīgā intelekta attīstībā, ieviešot sarežģītāku zināšanu attēlošanu.
Tādas ekspertu sistēmas kā MYCIN (kas diagnosticēja bakteriālas infekcijas) un DENDRAL (kas identificēja ķīmiskos savienojumus) organizēja informāciju strukturētās zināšanu bāzēs un izmantoja secinājumu dzinējus, lai izdarītu secinājumus. Pielietojot šo pieeju sarunu saskarnēs, tā ļāva tērzēšanas robotiem pāriet no vienkāršas modeļu salīdzināšanas uz kaut ko līdzīgu spriešanai – vismaz šaurās jomās.
Uzņēmumi sāka ieviest praktiskus pielietojumus, piemēram, automatizētas klientu apkalpošanas sistēmas, izmantojot šo tehnoloģiju. Šīs sistēmas parasti izmantoja lēmumu kokus un uz izvēlnēm balstītas mijiedarbības, nevis brīvas formas sarunas, taču tās bija agrīni mēģinājumi automatizēt mijiedarbību, kas iepriekš prasīja cilvēka iejaukšanos.
Ierobežojumi joprojām bija ievērojami. Šīs sistēmas bija trauslas, nespējot eleganti apstrādāt negaidītus ievades datus. Tās prasīja milzīgas pūles no zināšanu inženieriem, lai manuāli kodētu informāciju un noteikumus. Un, iespējams, vissvarīgākais, viņi joprojām nespēja patiesi izprast dabisko valodu tās pilnajā sarežģītībā un neskaidrībā.
Neskatoties uz to, šajā laikmetā tika izveidoti svarīgi jēdzieni, kas vēlāk kļuva izšķiroši mūsdienu sarunvalodas mākslīgajam intelektam: strukturēta zināšanu attēlošana, loģiska secināšana un jomu specializācija. Tika likts pamats paradigmas maiņai, lai gan tehnoloģijas vēl nebija pilnībā attīstītas.
Tādas ekspertu sistēmas kā MYCIN (kas diagnosticēja bakteriālas infekcijas) un DENDRAL (kas identificēja ķīmiskos savienojumus) organizēja informāciju strukturētās zināšanu bāzēs un izmantoja secinājumu dzinējus, lai izdarītu secinājumus. Pielietojot šo pieeju sarunu saskarnēs, tā ļāva tērzēšanas robotiem pāriet no vienkāršas modeļu salīdzināšanas uz kaut ko līdzīgu spriešanai – vismaz šaurās jomās.
Uzņēmumi sāka ieviest praktiskus pielietojumus, piemēram, automatizētas klientu apkalpošanas sistēmas, izmantojot šo tehnoloģiju. Šīs sistēmas parasti izmantoja lēmumu kokus un uz izvēlnēm balstītas mijiedarbības, nevis brīvas formas sarunas, taču tās bija agrīni mēģinājumi automatizēt mijiedarbību, kas iepriekš prasīja cilvēka iejaukšanos.
Ierobežojumi joprojām bija ievērojami. Šīs sistēmas bija trauslas, nespējot eleganti apstrādāt negaidītus ievades datus. Tās prasīja milzīgas pūles no zināšanu inženieriem, lai manuāli kodētu informāciju un noteikumus. Un, iespējams, vissvarīgākais, viņi joprojām nespēja patiesi izprast dabisko valodu tās pilnajā sarežģītībā un neskaidrībā.
Neskatoties uz to, šajā laikmetā tika izveidoti svarīgi jēdzieni, kas vēlāk kļuva izšķiroši mūsdienu sarunvalodas mākslīgajam intelektam: strukturēta zināšanu attēlošana, loģiska secināšana un jomu specializācija. Tika likts pamats paradigmas maiņai, lai gan tehnoloģijas vēl nebija pilnībā attīstītas.
Dabiskās valodas izpratne: skaitļošanas lingvistikas izrāviens
Deviņdesmito gadu beigās un divtūkstošo gadu sākumā arvien lielāka uzmanība tika pievērsta dabiskās valodas apstrādei (NLP) un skaitļošanas lingvistikai. Tā vietā, lai mēģinātu manuāli kodēt noteikumus katrai iespējamai mijiedarbībai, pētnieki sāka izstrādāt statistikas metodes, lai palīdzētu datoriem izprast cilvēka valodas raksturīgos modeļus.
Šīs pārmaiņas veicināja vairāki faktori: pieaugošā skaitļošanas jauda, labāki algoritmi un, kas ir ļoti svarīgi, lielu teksta korpusu pieejamība, kurus varēja analizēt, lai identificētu lingvistiskos modeļus. Sistēmās sāka iekļaut tādas metodes kā:
Runas daļu atzīmēšana: vārdu funkcionalitātes noteikšana kā lietvārdi, darbības vārdi, īpašības vārdi utt.
Nosauktu entītiju atpazīšana: īpašvārdu (cilvēku, organizāciju, atrašanās vietu) noteikšana un klasificēšana.
Noskaņojuma analīze: teksta emocionālā toņa noteikšana.
Parsēšana: teikumu struktūras analīze, lai identificētu gramatiskās attiecības starp vārdiem.
Viens ievērojams sasniegums bija IBM Watson, kas slaveni uzvarēja cilvēku čempionus viktorīnas šovā Jeopardy! 2011. gadā. Lai gan Vatsons nebija gluži sarunu sistēma, tas demonstrēja nepieredzētas spējas saprast dabiskās valodas jautājumus, meklēt plašās zināšanu krātuvēs un formulēt atbildes – spējas, kas izrādījās būtiskas nākamās paaudzes tērzēšanas robotiem.
Drīz sekoja komerciālas lietojumprogrammas. Apple Siri tika laista klajā 2011. gadā, nodrošinot sarunu saskarnes plašākai patērētāju lokam. Lai gan Siri bija ierobežots ar mūsdienu standartiem, tas bija ievērojams progress, padarot mākslīgā intelekta palīgus pieejamus ikdienas lietotājiem. Sekoja Microsoft Cortana, Google Assistant un Amazon Alexa, katrs virzot uz priekšu jaunākās tehnoloģijas patērētājiem paredzētajā sarunu mākslīgajā intelektā.
Neskatoties uz šiem sasniegumiem, šī laikmeta sistēmām joprojām bija grūtības ar kontekstu, loģisku spriešanu un patiesi dabiski skanošu atbilžu ģenerēšanu. Tās bija sarežģītākas nekā to uz noteikumiem balstītie priekšteči, taču to izpratne par valodu un pasauli joprojām bija principiāli ierobežota.
Šīs pārmaiņas veicināja vairāki faktori: pieaugošā skaitļošanas jauda, labāki algoritmi un, kas ir ļoti svarīgi, lielu teksta korpusu pieejamība, kurus varēja analizēt, lai identificētu lingvistiskos modeļus. Sistēmās sāka iekļaut tādas metodes kā:
Runas daļu atzīmēšana: vārdu funkcionalitātes noteikšana kā lietvārdi, darbības vārdi, īpašības vārdi utt.
Nosauktu entītiju atpazīšana: īpašvārdu (cilvēku, organizāciju, atrašanās vietu) noteikšana un klasificēšana.
Noskaņojuma analīze: teksta emocionālā toņa noteikšana.
Parsēšana: teikumu struktūras analīze, lai identificētu gramatiskās attiecības starp vārdiem.
Viens ievērojams sasniegums bija IBM Watson, kas slaveni uzvarēja cilvēku čempionus viktorīnas šovā Jeopardy! 2011. gadā. Lai gan Vatsons nebija gluži sarunu sistēma, tas demonstrēja nepieredzētas spējas saprast dabiskās valodas jautājumus, meklēt plašās zināšanu krātuvēs un formulēt atbildes – spējas, kas izrādījās būtiskas nākamās paaudzes tērzēšanas robotiem.
Drīz sekoja komerciālas lietojumprogrammas. Apple Siri tika laista klajā 2011. gadā, nodrošinot sarunu saskarnes plašākai patērētāju lokam. Lai gan Siri bija ierobežots ar mūsdienu standartiem, tas bija ievērojams progress, padarot mākslīgā intelekta palīgus pieejamus ikdienas lietotājiem. Sekoja Microsoft Cortana, Google Assistant un Amazon Alexa, katrs virzot uz priekšu jaunākās tehnoloģijas patērētājiem paredzētajā sarunu mākslīgajā intelektā.
Neskatoties uz šiem sasniegumiem, šī laikmeta sistēmām joprojām bija grūtības ar kontekstu, loģisku spriešanu un patiesi dabiski skanošu atbilžu ģenerēšanu. Tās bija sarežģītākas nekā to uz noteikumiem balstītie priekšteči, taču to izpratne par valodu un pasauli joprojām bija principiāli ierobežota.
Mašīnmācīšanās un uz datiem balstīta pieeja
2010. gadu vidus iezīmēja vēl vienu paradigmas maiņu sarunu mākslīgajā intelektā, plaši ieviešot mašīnmācīšanās metodes. Tā vietā, lai paļautos uz ar rokām izstrādātiem noteikumiem vai ierobežotiem statistikas modeļiem, inženieri sāka veidot sistēmas, kas varēja mācīties modeļus tieši no datiem – un daudz no tiem.
Šajā laikmetā nodomu klasifikācija un entītiju ieguve kļuva par sarunu arhitektūras pamatkomponentiem. Kad lietotājs veica pieprasījumu, sistēma:
Klasificēja kopējo nodomu (piemēram, lidojuma rezervēšana, laika apstākļu pārbaude, mūzikas atskaņošana)
Ieguva atbilstošas entītijas (piemēram, atrašanās vietas, datumus, dziesmu nosaukumus)
Saistīja tās ar konkrētām darbībām vai atbildēm
Facebook (tagad Meta) Messenger platformas palaišana 2016. gadā ļāva izstrādātājiem izveidot tērzēšanas robotus, kas varēja sasniegt miljoniem lietotāju, izraisot komerciālas intereses vilni. Daudzi uzņēmumi steidzās ieviest tērzēšanas robotus, lai gan rezultāti bija dažādi. Agrīnās komerciālās ieviešanas bieži vien neapmierināja lietotājus ar ierobežotu izpratni un stingrām sarunu plūsmām.
Šajā periodā attīstījās arī sarunu sistēmu tehniskā arhitektūra. Tipiskā pieeja ietvēra specializētu komponentu plūsmu:
Automātiska runas atpazīšana (balss saskarnēm)
Dabiskās valodas izpratne
Dialogu pārvaldība
Dabiskās valodas ģenerēšana
Teksta pārveidošana runā (balss saskarnēm)
Katru komponentu varēja optimizēt atsevišķi, tādējādi nodrošinot pakāpeniskus uzlabojumus. Tomēr šīs plūsmas arhitektūras dažkārt cieta no kļūdu izplatīšanās – kļūdas agrīnās stadijās izplatījās visā sistēmā.
Lai gan mašīnmācīšanās ievērojami uzlaboja iespējas, sistēmām joprojām bija grūtības saglabāt kontekstu garās sarunās, izprast netiešu informāciju un ģenerēt patiesi daudzveidīgas un dabiskas atbildes. Nākamajam sasniegumam būtu nepieciešama radikālāka pieeja.
Šajā laikmetā nodomu klasifikācija un entītiju ieguve kļuva par sarunu arhitektūras pamatkomponentiem. Kad lietotājs veica pieprasījumu, sistēma:
Klasificēja kopējo nodomu (piemēram, lidojuma rezervēšana, laika apstākļu pārbaude, mūzikas atskaņošana)
Ieguva atbilstošas entītijas (piemēram, atrašanās vietas, datumus, dziesmu nosaukumus)
Saistīja tās ar konkrētām darbībām vai atbildēm
Facebook (tagad Meta) Messenger platformas palaišana 2016. gadā ļāva izstrādātājiem izveidot tērzēšanas robotus, kas varēja sasniegt miljoniem lietotāju, izraisot komerciālas intereses vilni. Daudzi uzņēmumi steidzās ieviest tērzēšanas robotus, lai gan rezultāti bija dažādi. Agrīnās komerciālās ieviešanas bieži vien neapmierināja lietotājus ar ierobežotu izpratni un stingrām sarunu plūsmām.
Šajā periodā attīstījās arī sarunu sistēmu tehniskā arhitektūra. Tipiskā pieeja ietvēra specializētu komponentu plūsmu:
Automātiska runas atpazīšana (balss saskarnēm)
Dabiskās valodas izpratne
Dialogu pārvaldība
Dabiskās valodas ģenerēšana
Teksta pārveidošana runā (balss saskarnēm)
Katru komponentu varēja optimizēt atsevišķi, tādējādi nodrošinot pakāpeniskus uzlabojumus. Tomēr šīs plūsmas arhitektūras dažkārt cieta no kļūdu izplatīšanās – kļūdas agrīnās stadijās izplatījās visā sistēmā.
Lai gan mašīnmācīšanās ievērojami uzlaboja iespējas, sistēmām joprojām bija grūtības saglabāt kontekstu garās sarunās, izprast netiešu informāciju un ģenerēt patiesi daudzveidīgas un dabiskas atbildes. Nākamajam sasniegumam būtu nepieciešama radikālāka pieeja.
Transformatoru revolūcija: neironu valodas modeļi
2017. gads iezīmēja pavērsiena punktu mākslīgā intelekta vēsturē, publicējot grāmatu “Attention Is All You Need” (Uzmanība ir viss, kas jums nepieciešams), kurā tika iepazīstināta ar Transformer arhitektūru, kas revolucionizēja dabiskās valodas apstrādi. Atšķirībā no iepriekšējām pieejām, kas apstrādāja tekstu secīgi, Transformers varēja vienlaikus aplūkot visu fragmentu, ļaujot tiem labāk uztvert attiecības starp vārdiem neatkarīgi no to attāluma viens no otra.
Šis jauninājums ļāva izstrādāt arvien jaudīgākus valodas modeļus. 2018. gadā Google ieviesa BERT (Bidirectional Encoder Representations from Transformers), kas ievērojami uzlaboja veiktspēju dažādos valodas izpratnes uzdevumos. 2019. gadā OpenAI izlaida GPT-2, demonstrējot vēl nebijušas spējas ģenerēt saskaņotu, kontekstuāli atbilstošu tekstu.
Visdramatiskākais lēciens notika 2020. gadā ar GPT-3, kas tika mērogots līdz 175 miljardiem parametru (salīdzinājumā ar GPT-2 1,5 miljardiem). Šis milzīgais mēroga pieaugums apvienojumā ar arhitektūras uzlabojumiem radīja kvalitatīvi atšķirīgas iespējas. GPT-3 varēja ģenerēt ievērojami cilvēkam līdzīgu tekstu, saprast kontekstu tūkstošiem vārdu un pat veikt uzdevumus, kuriem tas nebija tieši apmācīts.
Sarunu mākslīgā intelekta jomā šie sasniegumi tika ieviesti tērzēšanas robotos, kas varēja:
Uzturēt saskaņotas sarunas daudzos posmos
Izprast niansētus vaicājumus bez īpašas apmācības
Ģenerēt dažādas, kontekstuāli atbilstošas atbildes
Pielāgot savu toni un stilu lietotājam
Risināt neskaidrības un nepieciešamības gadījumā precizēt
ChatGPT izlaišana 2022. gada beigās šīs iespējas padarīja plaši pieejamas, piesaistot vairāk nekā miljonu lietotāju dažu dienu laikā pēc tā palaišanas. Pēkšņi plašai sabiedrībai bija pieejams sarunu mākslīgais intelekts, kas šķita kvalitatīvi atšķirīgs no visa iepriekšējā – elastīgāks, zinošāks un dabiskāks mijiedarbībā.
Drīz sekoja komerciāla ieviešana, uzņēmumiem iekļaujot lielus valodu modeļus savās klientu apkalpošanas platformās, satura veidošanas rīkos un produktivitātes lietojumprogrammās. Strauja ieviešana atspoguļoja gan tehnoloģisko lēcienu, gan intuitīvo saskarni, ko šie modeļi nodrošināja – saruna galu galā ir dabiskākais veids, kā cilvēki sazinās.
Šis jauninājums ļāva izstrādāt arvien jaudīgākus valodas modeļus. 2018. gadā Google ieviesa BERT (Bidirectional Encoder Representations from Transformers), kas ievērojami uzlaboja veiktspēju dažādos valodas izpratnes uzdevumos. 2019. gadā OpenAI izlaida GPT-2, demonstrējot vēl nebijušas spējas ģenerēt saskaņotu, kontekstuāli atbilstošu tekstu.
Visdramatiskākais lēciens notika 2020. gadā ar GPT-3, kas tika mērogots līdz 175 miljardiem parametru (salīdzinājumā ar GPT-2 1,5 miljardiem). Šis milzīgais mēroga pieaugums apvienojumā ar arhitektūras uzlabojumiem radīja kvalitatīvi atšķirīgas iespējas. GPT-3 varēja ģenerēt ievērojami cilvēkam līdzīgu tekstu, saprast kontekstu tūkstošiem vārdu un pat veikt uzdevumus, kuriem tas nebija tieši apmācīts.
Sarunu mākslīgā intelekta jomā šie sasniegumi tika ieviesti tērzēšanas robotos, kas varēja:
Uzturēt saskaņotas sarunas daudzos posmos
Izprast niansētus vaicājumus bez īpašas apmācības
Ģenerēt dažādas, kontekstuāli atbilstošas atbildes
Pielāgot savu toni un stilu lietotājam
Risināt neskaidrības un nepieciešamības gadījumā precizēt
ChatGPT izlaišana 2022. gada beigās šīs iespējas padarīja plaši pieejamas, piesaistot vairāk nekā miljonu lietotāju dažu dienu laikā pēc tā palaišanas. Pēkšņi plašai sabiedrībai bija pieejams sarunu mākslīgais intelekts, kas šķita kvalitatīvi atšķirīgs no visa iepriekšējā – elastīgāks, zinošāks un dabiskāks mijiedarbībā.
Drīz sekoja komerciāla ieviešana, uzņēmumiem iekļaujot lielus valodu modeļus savās klientu apkalpošanas platformās, satura veidošanas rīkos un produktivitātes lietojumprogrammās. Strauja ieviešana atspoguļoja gan tehnoloģisko lēcienu, gan intuitīvo saskarni, ko šie modeļi nodrošināja – saruna galu galā ir dabiskākais veids, kā cilvēki sazinās.
Pārbaudiet SAVU Biznesu Minūtes
Izveidojiet savu kontu un palaidiet savu AI chatbot dažu minūšu laikā. Pilnībā pielāgojams, nav nepieciešama kodēšana - sāciet iesaistīt savus klientus tūlīt!
Gatavs dažu minūšu laikā
Nav nepieciešama kodēšana
100% droši
Multimodālas iespējas: vairāk nekā tikai teksta sarunas
Lai gan sarunvalodas mākslīgā intelekta attīstībā dominējis teksts, pēdējos gados ir vērojama tendence uz multimodālām sistēmām, kas spēj saprast un ģenerēt vairāku veidu multividi. Šī evolūcija atspoguļo fundamentālu patiesību par cilvēku komunikāciju – mēs ne tikai lietojam vārdus; mēs žestikulējam, rādām attēlus, zīmējam diagrammas un izmantojam savu vidi, lai nodotu nozīmi.
Redzes valodas modeļi, piemēram, DALL-E, Midjourney un Stable Diffusion, demonstrēja spēju ģenerēt attēlus no teksta aprakstiem, savukārt tādi modeļi kā GPT-4 ar redzes iespējām varēja analizēt attēlus un tos inteliģenti apspriest. Tas pavēra jaunas iespējas sarunvalodas saskarnēm:
Klientu apkalpošanas roboti, kas var analizēt bojātu produktu fotoattēlus
Iepirkšanās asistenti, kas var identificēt preces no attēliem un atrast līdzīgus produktus
Izglītojoši rīki, kas var izskaidrot diagrammas un vizuālos jēdzienus
Pieejamības funkcijas, kas var aprakstīt attēlus lietotājiem ar redzes traucējumiem
Arī balss iespējas ir ievērojami attīstījušās. Agrīnās runas saskarnes, piemēram, IVR (Interactive Voice Response) sistēmas, bija pazīstamas ar to, ka tās bija nomācošas, jo aprobežojās ar stingrām komandām un izvēļņu struktūrām. Mūsdienu balss asistenti spēj saprast dabiskas runas modeļus, ņemt vērā dažādus akcentus un runas traucējumus, kā arī reaģēt ar arvien dabiskāk skanošām sintezētām balsīm.
Šo spēju apvienojums rada patiesi multimodālu sarunvalodas mākslīgo intelektu (AI), kas var nemanāmi pārslēgties starp dažādiem saziņas režīmiem atkarībā no konteksta un lietotāja vajadzībām. Lietotājs var sākt ar teksta jautājumu par printera salabošanu, nosūtīt kļūdas ziņojuma fotoattēlu, saņemt diagrammu, kurā izceltas atbilstošās pogas, un pēc tam pārslēgties uz balss norādījumiem, kamēr viņa rokas ir aizņemtas ar remontu.
Šī multimodālā pieeja ir ne tikai tehnisks progress, bet arī fundamentāla pāreja uz dabiskāku cilvēka un datora mijiedarbību – lietotāju sastapšana jebkurā saziņas režīmā, kas vislabāk atbilst viņu pašreizējam kontekstam un vajadzībām.
Redzes valodas modeļi, piemēram, DALL-E, Midjourney un Stable Diffusion, demonstrēja spēju ģenerēt attēlus no teksta aprakstiem, savukārt tādi modeļi kā GPT-4 ar redzes iespējām varēja analizēt attēlus un tos inteliģenti apspriest. Tas pavēra jaunas iespējas sarunvalodas saskarnēm:
Klientu apkalpošanas roboti, kas var analizēt bojātu produktu fotoattēlus
Iepirkšanās asistenti, kas var identificēt preces no attēliem un atrast līdzīgus produktus
Izglītojoši rīki, kas var izskaidrot diagrammas un vizuālos jēdzienus
Pieejamības funkcijas, kas var aprakstīt attēlus lietotājiem ar redzes traucējumiem
Arī balss iespējas ir ievērojami attīstījušās. Agrīnās runas saskarnes, piemēram, IVR (Interactive Voice Response) sistēmas, bija pazīstamas ar to, ka tās bija nomācošas, jo aprobežojās ar stingrām komandām un izvēļņu struktūrām. Mūsdienu balss asistenti spēj saprast dabiskas runas modeļus, ņemt vērā dažādus akcentus un runas traucējumus, kā arī reaģēt ar arvien dabiskāk skanošām sintezētām balsīm.
Šo spēju apvienojums rada patiesi multimodālu sarunvalodas mākslīgo intelektu (AI), kas var nemanāmi pārslēgties starp dažādiem saziņas režīmiem atkarībā no konteksta un lietotāja vajadzībām. Lietotājs var sākt ar teksta jautājumu par printera salabošanu, nosūtīt kļūdas ziņojuma fotoattēlu, saņemt diagrammu, kurā izceltas atbilstošās pogas, un pēc tam pārslēgties uz balss norādījumiem, kamēr viņa rokas ir aizņemtas ar remontu.
Šī multimodālā pieeja ir ne tikai tehnisks progress, bet arī fundamentāla pāreja uz dabiskāku cilvēka un datora mijiedarbību – lietotāju sastapšana jebkurā saziņas režīmā, kas vislabāk atbilst viņu pašreizējam kontekstam un vajadzībām.
Izguves papildināta ģenerēšana: mākslīgā intelekta pamatošana faktos
Neskatoties uz iespaidīgajām iespējām, lieliem valodu modeļiem ir raksturīgi ierobežojumi. Tie var "halucinēt" informāciju, pārliecinoši norādot ticami skanošus, bet nepareizus faktus. To zināšanas ir ierobežotas ar to, kas bija viņu apmācības datos, radot zināšanu robeždatumu. Un tiem trūkst iespējas piekļūt reāllaika informācijai vai specializētām datubāzēm, ja vien tas nav īpaši izstrādāts.
Izguves papildinātā ģenerēšana (RAG) parādījās kā risinājums šīm problēmām. Tā vietā, lai paļautos tikai uz apmācības laikā apgūtajiem parametriem, RAG sistēmas apvieno valodu modeļu ģeneratīvās spējas ar izguves mehānismiem, kas var piekļūt ārējiem zināšanu avotiem. Tipiska RAG arhitektūra darbojas šādi:
Sistēma saņem lietotāja vaicājumu
Tā meklē atbilstošās zināšanu bāzēs informāciju, kas attiecas uz vaicājumu
Tā ievada gan vaicājumu, gan iegūto informāciju valodas modelī
Modelis ģenerē atbildi, kuras pamatā ir iegūtie fakti
Šī pieeja piedāvā vairākas priekšrocības:
Precīzākas, faktoloģiskas atbildes, balstot ģenerēšanu uz pārbaudītu informāciju
Iespēja piekļūt aktuālākai informācijai arī ārpus modeļa apmācības robežvērtībām
Specializētas zināšanas no konkrētai jomai specifiskiem avotiem, piemēram, uzņēmuma dokumentācijas
Caurspīdīgums un attiecinājums, citējot informācijas avotus
Uzņēmumiem, kas ievieš sarunvalodas mākslīgo intelektu, RAG ir izrādījies īpaši vērtīgs klientu apkalpošanas lietojumprogrammās. Piemēram, banku tērzēšanas robots var piekļūt jaunākajiem politikas dokumentiem, konta informācijai un darījumu ierakstiem, lai sniegtu precīzas, personalizētas atbildes, kas nebūtu iespējams ar atsevišķu valodas modeli.
RAG sistēmu attīstība turpinās, uzlabojoties izguves precizitātei, ieviešot sarežģītākas metodes iegūtās informācijas integrēšanai ar ģenerēto tekstu un labākus mehānismus dažādu informācijas avotu uzticamības novērtēšanai.
Izguves papildinātā ģenerēšana (RAG) parādījās kā risinājums šīm problēmām. Tā vietā, lai paļautos tikai uz apmācības laikā apgūtajiem parametriem, RAG sistēmas apvieno valodu modeļu ģeneratīvās spējas ar izguves mehānismiem, kas var piekļūt ārējiem zināšanu avotiem. Tipiska RAG arhitektūra darbojas šādi:
Sistēma saņem lietotāja vaicājumu
Tā meklē atbilstošās zināšanu bāzēs informāciju, kas attiecas uz vaicājumu
Tā ievada gan vaicājumu, gan iegūto informāciju valodas modelī
Modelis ģenerē atbildi, kuras pamatā ir iegūtie fakti
Šī pieeja piedāvā vairākas priekšrocības:
Precīzākas, faktoloģiskas atbildes, balstot ģenerēšanu uz pārbaudītu informāciju
Iespēja piekļūt aktuālākai informācijai arī ārpus modeļa apmācības robežvērtībām
Specializētas zināšanas no konkrētai jomai specifiskiem avotiem, piemēram, uzņēmuma dokumentācijas
Caurspīdīgums un attiecinājums, citējot informācijas avotus
Uzņēmumiem, kas ievieš sarunvalodas mākslīgo intelektu, RAG ir izrādījies īpaši vērtīgs klientu apkalpošanas lietojumprogrammās. Piemēram, banku tērzēšanas robots var piekļūt jaunākajiem politikas dokumentiem, konta informācijai un darījumu ierakstiem, lai sniegtu precīzas, personalizētas atbildes, kas nebūtu iespējams ar atsevišķu valodas modeli.
RAG sistēmu attīstība turpinās, uzlabojoties izguves precizitātei, ieviešot sarežģītākas metodes iegūtās informācijas integrēšanai ar ģenerēto tekstu un labākus mehānismus dažādu informācijas avotu uzticamības novērtēšanai.
Cilvēka un mākslīgā intelekta sadarbības modelis: pareizā līdzsvara atrašana
Līdz ar sarunu mākslīgā intelekta (MI) iespēju paplašināšanos ir attīstījušās attiecības starp cilvēkiem un MI sistēmām. Agrīnie tērzēšanas roboti tika nepārprotami pozicionēti kā rīki – ierobežota darbības joma un acīmredzami necilvēciska mijiedarbība. Mūsdienu sistēmas sapludina šīs robežas, radot jaunus jautājumus par to, kā izstrādāt efektīvu cilvēka un MI sadarbību.
Mūsdienās veiksmīgākās ieviešanas notiek pēc sadarbības modeļa, kurā:
MI apstrādā ikdienas, atkārtotus vaicājumus, kuriem nav nepieciešama cilvēka spriestspēja
Cilvēki koncentrējas uz sarežģītiem gadījumiem, kuriem nepieciešama empātija, ētiska spriešana vai radoša problēmu risināšana
Sistēma zina savus ierobežojumus un vienmērīgi pāriet uz cilvēku aģentiem, kad tas ir nepieciešams
Pāreja starp MI un cilvēku atbalstu lietotājam ir nemanāma
Cilvēku aģentiem ir pilns sarunas vēstures konteksts ar MI
MI turpina mācīties no cilvēku iejaukšanās, pakāpeniski paplašinot savas iespējas
Šī pieeja atzīst, ka sarunu mākslīgajam intelektam nevajadzētu censties pilnībā aizstāt cilvēku mijiedarbību, bet gan to papildināt – apstrādājot liela apjoma, vienkāršus vaicājumus, kas patērē cilvēku aģentu laiku, vienlaikus nodrošinot, ka sarežģīti jautājumi nonāk pie atbilstošas cilvēku eksperta.
Šī modeļa ieviešana dažādās nozarēs atšķiras. Veselības aprūpē mākslīgā intelekta tērzēšanas roboti varētu veikt tikšanās plānošanu un pamata simptomu pārbaudi, vienlaikus nodrošinot, ka medicīnisko padomu sniedz kvalificēti speciālisti. Juridisko pakalpojumu jomā mākslīgais intelekts varētu palīdzēt dokumentu sagatavošanā un izpētē, atstājot interpretāciju un stratēģiju juristu ziņā. Klientu apkalpošanas jomā mākslīgais intelekts var atrisināt bieži sastopamas problēmas, vienlaikus nododot sarežģītas problēmas specializētiem aģentiem.
Tā kā mākslīgā intelekta iespējas turpina attīstīties, robeža starp to, kam nepieciešama cilvēka iesaistīšanās, un to, ko var automatizēt, mainīsies, taču pamatprincips paliek nemainīgs: efektīvam sarunvalodas mākslīgajam intelektam vajadzētu uzlabot cilvēka spējas, nevis vienkārši tās aizstāt.
Mūsdienās veiksmīgākās ieviešanas notiek pēc sadarbības modeļa, kurā:
MI apstrādā ikdienas, atkārtotus vaicājumus, kuriem nav nepieciešama cilvēka spriestspēja
Cilvēki koncentrējas uz sarežģītiem gadījumiem, kuriem nepieciešama empātija, ētiska spriešana vai radoša problēmu risināšana
Sistēma zina savus ierobežojumus un vienmērīgi pāriet uz cilvēku aģentiem, kad tas ir nepieciešams
Pāreja starp MI un cilvēku atbalstu lietotājam ir nemanāma
Cilvēku aģentiem ir pilns sarunas vēstures konteksts ar MI
MI turpina mācīties no cilvēku iejaukšanās, pakāpeniski paplašinot savas iespējas
Šī pieeja atzīst, ka sarunu mākslīgajam intelektam nevajadzētu censties pilnībā aizstāt cilvēku mijiedarbību, bet gan to papildināt – apstrādājot liela apjoma, vienkāršus vaicājumus, kas patērē cilvēku aģentu laiku, vienlaikus nodrošinot, ka sarežģīti jautājumi nonāk pie atbilstošas cilvēku eksperta.
Šī modeļa ieviešana dažādās nozarēs atšķiras. Veselības aprūpē mākslīgā intelekta tērzēšanas roboti varētu veikt tikšanās plānošanu un pamata simptomu pārbaudi, vienlaikus nodrošinot, ka medicīnisko padomu sniedz kvalificēti speciālisti. Juridisko pakalpojumu jomā mākslīgais intelekts varētu palīdzēt dokumentu sagatavošanā un izpētē, atstājot interpretāciju un stratēģiju juristu ziņā. Klientu apkalpošanas jomā mākslīgais intelekts var atrisināt bieži sastopamas problēmas, vienlaikus nododot sarežģītas problēmas specializētiem aģentiem.
Tā kā mākslīgā intelekta iespējas turpina attīstīties, robeža starp to, kam nepieciešama cilvēka iesaistīšanās, un to, ko var automatizēt, mainīsies, taču pamatprincips paliek nemainīgs: efektīvam sarunvalodas mākslīgajam intelektam vajadzētu uzlabot cilvēka spējas, nevis vienkārši tās aizstāt.
Nākotnes ainava: kurp virzās sarunvalodas mākslīgais intelekts
Raugoties nākotnē, vairākas jaunās tendences veido sarunvalodas mākslīgā intelekta nākotni. Šīs norises sola ne tikai pakāpeniskus uzlabojumus, bet arī potenciāli transformējošas pārmaiņas mūsu mijiedarbībā ar tehnoloģijām.
Personalizācija plašā mērogā: Nākotnes sistēmas arvien vairāk pielāgos savas atbildes ne tikai tiešajam kontekstam, bet arī katra lietotāja komunikācijas stilam, vēlmēm, zināšanu līmenim un attiecību vēsturei. Šī personalizācija padarīs mijiedarbību dabiskāku un atbilstošāku, lai gan tā rada svarīgus jautājumus par privātumu un datu izmantošanu.
Emocionālā inteliģence: Lai gan mūsdienu sistēmas var noteikt pamata noskaņojumu, nākotnes sarunvalodas mākslīgais intelekts attīstīs sarežģītāku emocionālo inteliģenci – atpazīstot smalkus emocionālos stāvokļus, atbilstoši reaģējot uz ciešanām vai neapmierinātību un attiecīgi pielāgojot savu toni un pieeju. Šī spēja būs īpaši vērtīga klientu apkalpošanas, veselības aprūpes un izglītības lietojumprogrammās.
Proaktīva palīdzība: Tā vietā, lai gaidītu skaidrus vaicājumus, nākamās paaudzes sarunvalodas sistēmas paredzēs vajadzības, pamatojoties uz kontekstu, lietotāja vēsturi un vides signāliem. Sistēma var pamanīt, ka plānojat vairākas tikšanās nepazīstamā pilsētā, un proaktīvi piedāvāt transporta iespējas vai laika prognozes.
Nevainojama multimodāla integrācija: Nākotnes sistēmas virzīsies tālāk par dažādu modalitāšu vienkāršu atbalstīšanu uz to nemanāmu integrāciju. Saruna varētu dabiski ritēt starp tekstu, balsi, attēliem un interaktīviem elementiem, izvēloties pareizo modalitāti katrai informācijas vienībai, neprasot tiešu lietotāja izvēli.
Specializētu jomu eksperti: Lai gan vispārējas nozīmes asistenti turpinās uzlaboties, mēs redzēsim arī augsti specializēta sarunvalodas mākslīgā intelekta (MI) pieaugumu ar padziļinātām zināšanām konkrētās jomās – juristi, kas izprot tiesu praksi un precedentus, medicīnas sistēmas ar visaptverošām zināšanām par zāļu mijiedarbību un ārstēšanas protokoliem, vai finanšu konsultanti, kas pārzina nodokļu kodeksus un investīciju stratēģijas.
Patiesi nepārtraukta mācīšanās: Nākotnes sistēmas pāries no periodiskas pārkvalifikācijas uz nepārtrauktu mācīšanos no mijiedarbības, laika gaitā kļūstot noderīgākas un personalizētākas, vienlaikus saglabājot atbilstošus privātuma aizsardzības pasākumus.
Neskatoties uz šīm aizraujošajām iespējām, joprojām pastāv izaicinājumi. Bažas par privātumu, aizspriedumu mazināšana, atbilstoša pārredzamība un pareiza cilvēka uzraudzības līmeņa noteikšana ir pastāvīgi jautājumi, kas veidos gan tehnoloģiju, gan tās regulējumu. Visveiksmīgākās ieviešanas būs tās, kas pārdomāti risinās šīs problēmas, vienlaikus sniedzot patiesu vērtību lietotājiem.
Ir skaidrs, ka sarunvalodas MI ir pārgājis no nišas tehnoloģijas uz galveno saskarnes paradigmu, kas arvien vairāk ietekmēs mūsu mijiedarbību ar digitālajām sistēmām. Evolucionārais ceļš no ELIZA vienkāršās modeļu saskaņošanas līdz mūsdienu sarežģītajiem valodu modeļiem ir viens no nozīmīgākajiem sasniegumiem cilvēka un datora mijiedarbībā, un ceļojums nebūt nav beidzies.
Personalizācija plašā mērogā: Nākotnes sistēmas arvien vairāk pielāgos savas atbildes ne tikai tiešajam kontekstam, bet arī katra lietotāja komunikācijas stilam, vēlmēm, zināšanu līmenim un attiecību vēsturei. Šī personalizācija padarīs mijiedarbību dabiskāku un atbilstošāku, lai gan tā rada svarīgus jautājumus par privātumu un datu izmantošanu.
Emocionālā inteliģence: Lai gan mūsdienu sistēmas var noteikt pamata noskaņojumu, nākotnes sarunvalodas mākslīgais intelekts attīstīs sarežģītāku emocionālo inteliģenci – atpazīstot smalkus emocionālos stāvokļus, atbilstoši reaģējot uz ciešanām vai neapmierinātību un attiecīgi pielāgojot savu toni un pieeju. Šī spēja būs īpaši vērtīga klientu apkalpošanas, veselības aprūpes un izglītības lietojumprogrammās.
Proaktīva palīdzība: Tā vietā, lai gaidītu skaidrus vaicājumus, nākamās paaudzes sarunvalodas sistēmas paredzēs vajadzības, pamatojoties uz kontekstu, lietotāja vēsturi un vides signāliem. Sistēma var pamanīt, ka plānojat vairākas tikšanās nepazīstamā pilsētā, un proaktīvi piedāvāt transporta iespējas vai laika prognozes.
Nevainojama multimodāla integrācija: Nākotnes sistēmas virzīsies tālāk par dažādu modalitāšu vienkāršu atbalstīšanu uz to nemanāmu integrāciju. Saruna varētu dabiski ritēt starp tekstu, balsi, attēliem un interaktīviem elementiem, izvēloties pareizo modalitāti katrai informācijas vienībai, neprasot tiešu lietotāja izvēli.
Specializētu jomu eksperti: Lai gan vispārējas nozīmes asistenti turpinās uzlaboties, mēs redzēsim arī augsti specializēta sarunvalodas mākslīgā intelekta (MI) pieaugumu ar padziļinātām zināšanām konkrētās jomās – juristi, kas izprot tiesu praksi un precedentus, medicīnas sistēmas ar visaptverošām zināšanām par zāļu mijiedarbību un ārstēšanas protokoliem, vai finanšu konsultanti, kas pārzina nodokļu kodeksus un investīciju stratēģijas.
Patiesi nepārtraukta mācīšanās: Nākotnes sistēmas pāries no periodiskas pārkvalifikācijas uz nepārtrauktu mācīšanos no mijiedarbības, laika gaitā kļūstot noderīgākas un personalizētākas, vienlaikus saglabājot atbilstošus privātuma aizsardzības pasākumus.
Neskatoties uz šīm aizraujošajām iespējām, joprojām pastāv izaicinājumi. Bažas par privātumu, aizspriedumu mazināšana, atbilstoša pārredzamība un pareiza cilvēka uzraudzības līmeņa noteikšana ir pastāvīgi jautājumi, kas veidos gan tehnoloģiju, gan tās regulējumu. Visveiksmīgākās ieviešanas būs tās, kas pārdomāti risinās šīs problēmas, vienlaikus sniedzot patiesu vērtību lietotājiem.
Ir skaidrs, ka sarunvalodas MI ir pārgājis no nišas tehnoloģijas uz galveno saskarnes paradigmu, kas arvien vairāk ietekmēs mūsu mijiedarbību ar digitālajām sistēmām. Evolucionārais ceļš no ELIZA vienkāršās modeļu saskaņošanas līdz mūsdienu sarežģītajiem valodu modeļiem ir viens no nozīmīgākajiem sasniegumiem cilvēka un datora mijiedarbībā, un ceļojums nebūt nav beidzies.





